Canadian Hydrogen Observatory: Insights to fuel…

Applying natural language processing techniques on Tweets
Communication on Twitter is now a must-do for all political leaders; it allows direct and instantaneous interactions with their electorate. A good example is the use of Twitter by the president of the United States: Donald Trump. He tweeted about 11 000 times in his first 33 months at the White House.
With the upcoming French municipal elections, we found it interesting to deep dive in the tweets made by the candidates for the Paris mayor’s race. We focused the analysis on the main candidates in the race (list as of February the 7th 2020, ranked from left-wing to right-wing):
As every Data Science project, we started with descriptive data analysis on every candidates and then went into data modelling on the two main candidates using sentiment analysis with the new deep learning architecture for French NLP (Natural Language Processing): FlauBERT and topic analysis thanks to Latent Dirichlet Allocation.
To collect the different tweets from the candidates, we have been using the Python library Tweepy. We retrieved all actions from the 07th of August 2019 to the 07th of February 2020, accounting for 19,375 actions from the candidates.
At this stage, we are not differentiating Tweets, Retweets, Quotes or Replies but will do later in the analysis. We are using the term “action” to name one of the four interactions above. For understanding purposes, please let us remind you the Twitter vocabulary:
For the Tweets of the candidates, we will also count the number interactions with other Twitter users:
As displayed below, we observe high discrepancies between candidates in their number of Twitter actions. Overall, the left-wing candidates are using much more Twitter than the right-wing ones. As the current mayor, A. Hidalgo is the candidate who communicates the most with more than 7,000 actions.
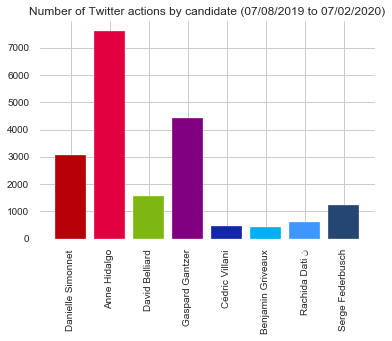
Note: In all graphics, the candidates are named according to the “name” of their Twitter account. Moreover, the colours identifying candidates are the ones used on their website.
Each action has a collection of 33 variables including interesting variables such as text, hashtags, number of retweets, number of favourites, creation date. We did some pre-processing to remove duplicates (due to the data collection process) and add variables to identify the nature of the action.
In order to estimate the feelings of the Twitter users against the two main candidates, we also collected the tweets between the 26th of January and the 09th of February having the hashtags #Hidalgo or #Dati.
If we inspect in detail the actions of each candidate, we understand why candidates have so many actions compared to others: they are not using Twitter the same way. Namely, active candidates are using a lot of Retweets, which is an effortless action, with no text to write on Retweet. The best example is A. Hidalgo: more than 80% of her Twitter actions are Retweets (as displayed below).
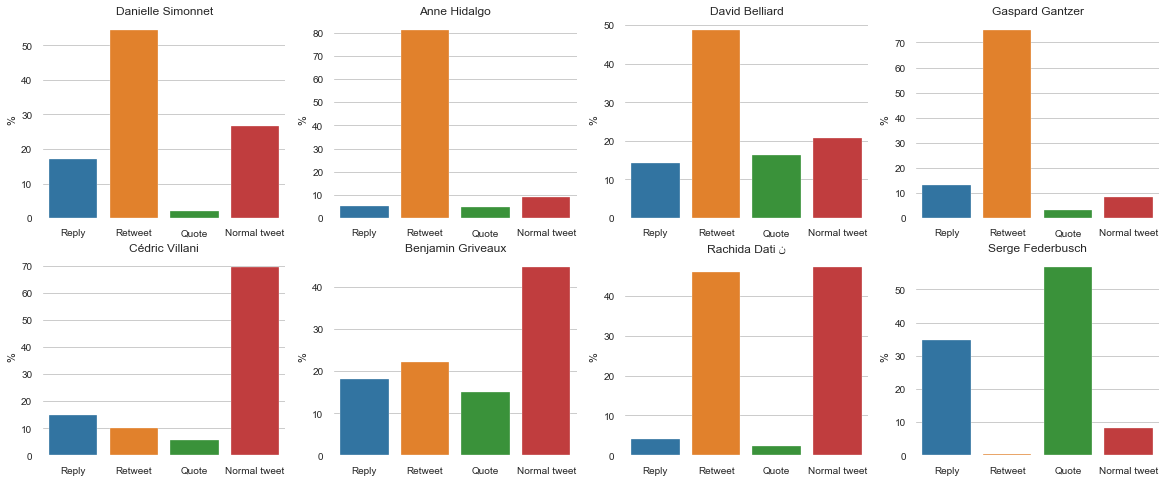
We can also analyse the number of actions based on the time of the year as shown below: the candidates’ actions are down-sampled into a 2 weeks period.
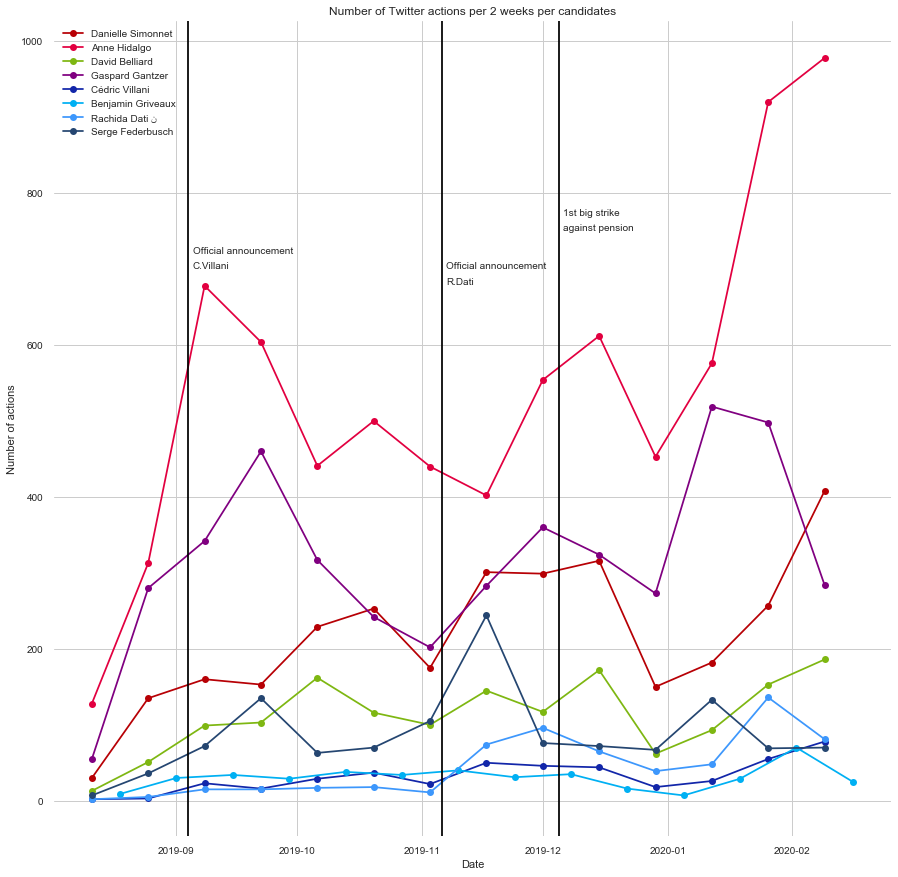
We observe that the number of actions has raised significantly after the summer holidays for all candidates with a break during Christmas holidays. An interesting fact is the increase of S. Federbusch’s actions volume after the official announcement of R. Dati as the candidate for “Les Républicains” and after C. Villani’s official candidate announcement outside the “En Marche” banner. On the contrary, the first big strike against pension did not trigger any noticeable effect on the Parisian candidates’ Twitter activity.
Checking the volume of content created is interesting but the interactions with their electorate is more important for political leaders. Below is the average number of Retweets and Favorites made on candidates’ Tweets.
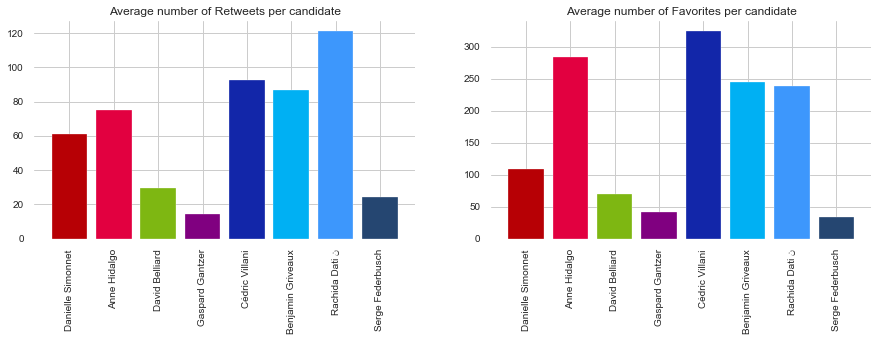
Despite not being backed-up by a political party, C. Villani has great interactions with more than 300 Favorites on average on his Tweets. The small number of Tweets written by C. Villani (312 in the period studied) indicates that he probably tweets only when he has a big announcement and therefore has high interactions on these ones.
Sentiment analysis aims at identifying opinions of a given Text. The opinions can vary but in our case, we tried to classify text according to Very negative, Negative, Positive or Very positive opinion.
We will now focus on the two candidates with the higher voting intentions: A. Hidalgo and R. Dati. We performed a sentiment analysis on their own tweets and on tweets containing their hashtags (#Hidalgo and #Dati).
To perform the sentiment analysis, we decided to use deep learning techniques (neural network). In November 2019, a BERT-like model has been open-sourced: FlauBERT. It achieves state-of-the-art results in numerous NLP tasks including sentence classification (the task required for sentiment analysis). We specifically used the huggingface implementation of FlauBERT on PyTorch.
As in computer vision tasks with VGG, NLP neural networks are pre-trained on a huge dataset and can be re-used with smaller training on specific tasks. We used the pre-trained weights of FlauBERT and re-trained on our GPU the last network layer on our specific task, namely sentiment analysis. This technique has numerous advantages:
To train the last layer of our model, we needed data with sentiment associated. We used the Webis Cross-Lingual Sentiment Dataset 2010, which has data labelled in English, French, German and Japanese. It provides 6,000 Amazon reviews in French associated with the rating associated (1, 2, 4 or 5 stars) for training. Comments with three stars are removed because of indecision on the sentiment of the text associated.

After 4 epochs on our GPU, our model achieved a 0,556 on the metric Matthews Correlation coefficient with four classes (representing “Very negative”, “Negative”, “Positive” and “Very positive” sentiment). The Matthews Correlation coefficient takes value between -1 and 1 (minimal value depends on the true distribution for multiclass cases); 1 being the perfect accuracy. We now had our fine-tuned model on the sentiment analysis task and applied it on the Tweets.
The Tweets from A. Hidalgo, as current Paris mayor, are overall very positive (see below). It is understandable as she is mainly promoting her own actions made during her mandate and her next projects.

On the contrary, R. Dati has in proportion much more “Very negative” and “Negative” Tweets as she is challenging the mandate of the current mayor alongside proposing her new ideas.
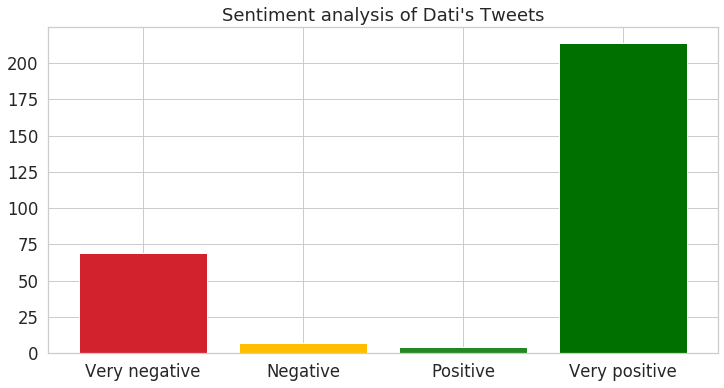
Note: We observe that the extreme classes “Very Positive” and “Very Negative” are much more represented than the middle ones. It can be because of the lover/hater attitude on Twitter but it also may be partly due to the training dataset that is imbalanced. For a production model, additional work should be performed on this topic to investigate the root causes.
We also wanted to identify the predominant topics for our top 2 candidates. In order to do so, we used the LDA (Latent Dirichlet Allocation) algorithm to identify ten topics per candidate based on their Tweets. We can have a sense of the topics by analysing the top words in each topic.
In the visualisations below, the grey bar indicates the overall term frequency in the corpus (all tweets for the selected candidate) and the red bar indicates the word frequency within the selected topic.
For R. Dati, the first topic is about delinquency. We can connect this topic to the current debate about the municipal police in Paris. As the right-wing candidate, it is not surprising that this topic comes first for R. Dati with more than a quarter of the tokens related to this topic.
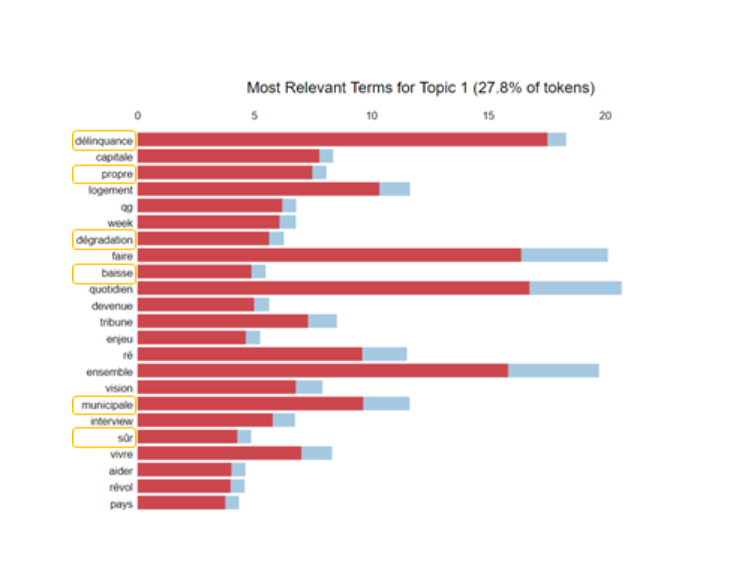
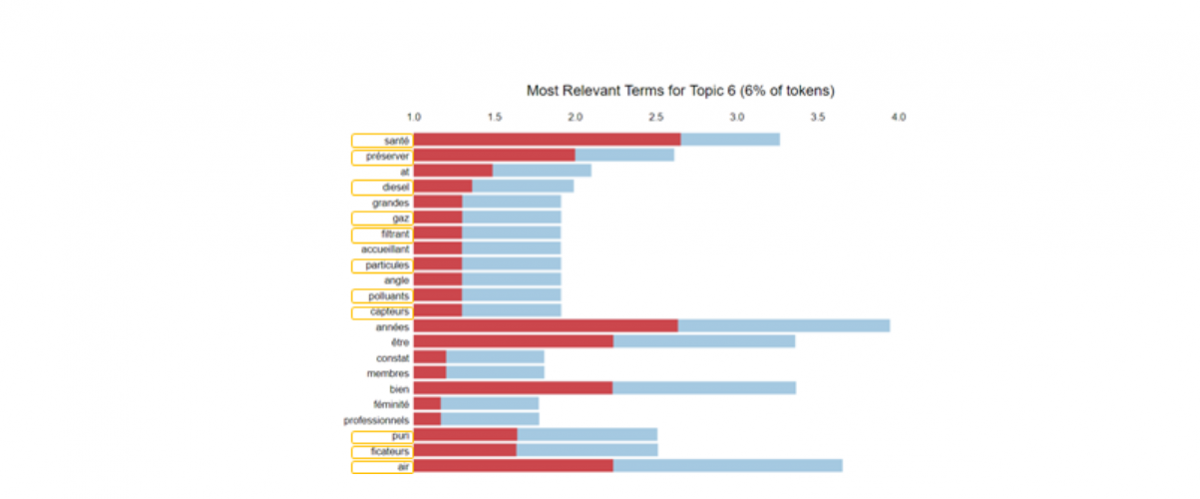
On the contrary, the air pollution is concerned by far less tokens in her Tweets with only 6% of the tokens related to the topic 6, which is clearly related to the air pollution in Paris.
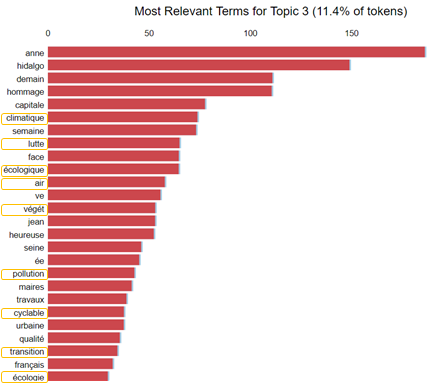
As the left-wing candidate, it is not a surprise to discover topics about ecology in the Tweets from A. Hidalgo. This topic is also correlated with the work she has done to have bike roads as we can see with the words “cyclable”, “travaux” (translated to : "cycle", "renovation work").
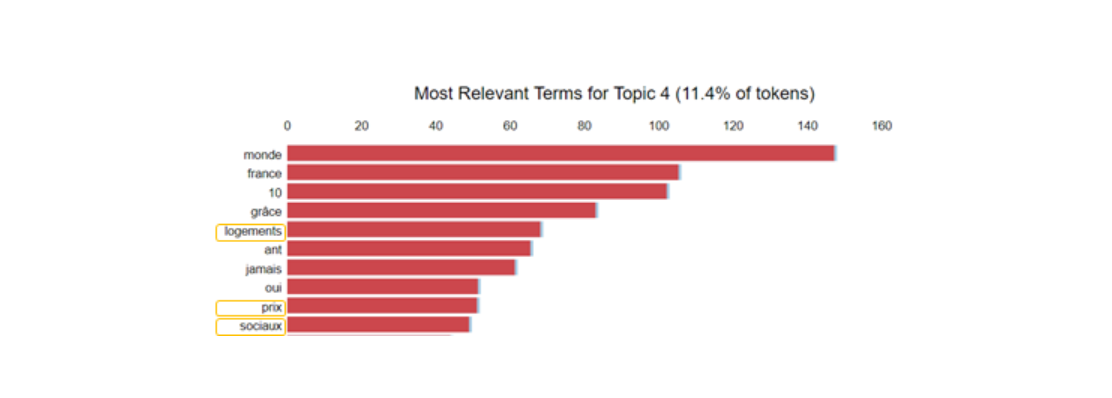
Another classic topic of the left-wing is social housing. It is a key topic for A. Hidalgo as the communist candidate I. Brossat (current housing deputy) has joined her list during the campaign. This topic accounts for more than 10% of her tokens.
Another classic topic of the left-wing is social housing. It is a key topic for A. Hidalgo as the communist candidate I. Brossat (current housing deputy) has joined her list during the campaign. This topic accounts for more than 10% of her tokens.
One of the key projects of A. Hidalgo as the Paris mayor is the renovation of 7 big places. This renovation has a focus on giving more space to pedestrians and vegetal areas. This topic is also identified by the LDA in Hidalgo’s Tweets with words like “place”, “bastille”, “jardins”, “espace” or “concorde” (translated to : "place", "bastille", "gardens", "space", "concorde").
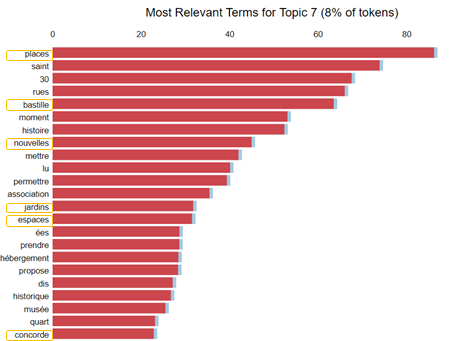
Note: As some tokens have no sense in French, the tokenizer (FlauBERT tokenizer) could have been replaced by a better one.
In this short analysis, we managed to extract some key insights via a rigorous data science process: data collection, data analysis and data modelling. We used a classic machine learning technique namely Latent Dirichlet Allocation but also deep learning technique with FlauBERT for sentiment analysis. We saw that political candidates were not using Twitter the same way, some predominantly using Retweets. The analysis of sentiment in Tweets gave us also insights about the candidates’ content strategy as well as their current dynamic in polls. Finally, the LDA extracted the key topics for each candidate, giving us a sense of their future projects as mayor.
Sia Partners has a proven track of assignments on various NLP tasks such as detecting fake online reviews, analysing sentiment on online reviews, qualifying regulatory updates, Chatbot or Speech-to-Text solution.


