Agentforce, the GenAI Agent by Salesforce

Last February, OpenAI released a new Natural Language Processing (NLP) software. The excellent performance of the model raises issues about preventing a potential misuse of these technological advances that have direct impacts on our lives.
Last February, OpenAI released a Natural Language Processing (NLP) algorithm called GPT-2. Surprisingly enough, and this is what made this publication go viral, OpenAI decided not to make its source code public (or at least the most developed version and its calibration parameters) explaining that it could be used maliciously for misinformation purposes.
Referring to the "DeepFakes" as a potential risk directly resulting from the improvement of such a technology accessible to all, the research team calls through this publication for more controls by public institutions and mention the danger that such a technology could represent for our democracy and our institutions.
Beyond the catchy headlines with apocalyptic tendencies and other hot twitter reactions, here is an exhaustive review of what has been revealed, the possible achievements of this model, its limitations and the lessons that can be drawn from such a breakthrough in the field of automated language processing and Machine Learning in general.
GPT-2 is a NLP-model (Natural Language processing) based on unsupervised machine learning methods. This model is able to complete and generate entire paragraphs of text with syntactical, grammatical and informative consistency. The model can read and understand a text, transcribe it, summarize it and is even able to answer questions about its structure or the information it contains. This is all possible, and that is where the big achievement from DeepMind lies, without any training specific to each of these tasks in particular and on any imaginable subject.
Until now, NLP research has focused on developing high-performance models on specific tasks for which they have been specifically trained and optimized. Examples include Neural Conversation Models (NCM), Neural Machine Translation (NMT) or Conversation Responding Models (CRM), most of which require semi-supervision during training via the implementation, usually manually, of rules previously implemented by the operator.
The technology behind this model is apparently nothing new, according to the scientific article accompanying the publication, this GPT-2 program would be an improvement on previous methods and not a new algorithm revolutionizing language modeling techniques. The approach used for GPT-2 is based on traditional language modeling methods assigning a probability P( w1, w2, ..., wm) to a sequence of words of size m, where wi represents each word. Each sequence of words then obtains a probability of occurrence determined by prior training of the model on a "WebText" database retrieved by scraping various sources from the web.
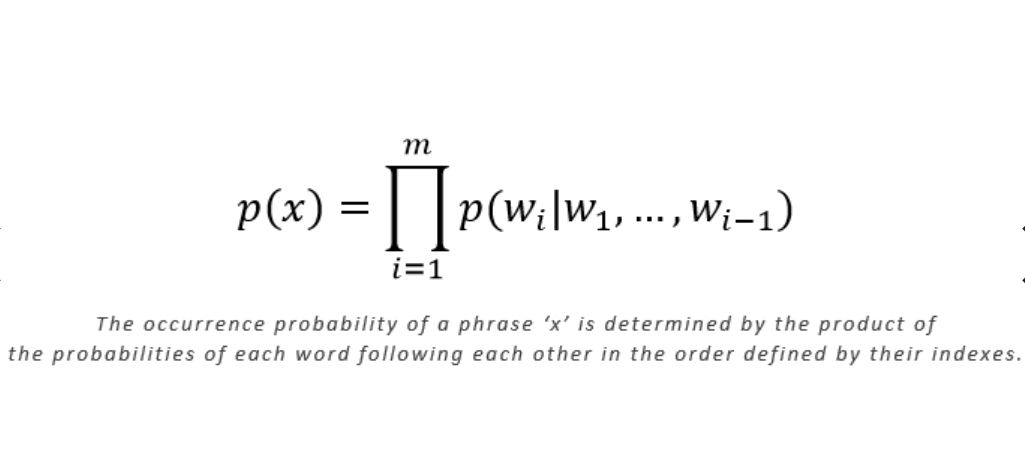
The innovation of GPT-2 seems to lie in the objective by the research team, to use the so-called Zero-shot learning method to evaluate the performance of the tool, and therefore to train it (Example: Recognize any object that has never been previously represented in the training database). In the case of language processing, it is a matter of entering a text that has never been learned previously by the model and assessing the consistency of the program's response to it.
The Zero-shot learning method uses class and word embedding or "word immersion", associating a vector and thus a continuous representation in a space to a discrete variable (a class, or here a word). This allows the algorithm to recognize texts that are not represented in the test set and associate them with themes and thus with other words known to the model, which have been previously processed in the learning phase.
According to OpenAI, the model would often take several attempts to generate acceptable text according to syntactic and contextual consistency criteria. Indeed, sometimes the algorithm refers to impossible physical phenomena (such as a fire lighting up under the ocean). The model would be particularly effective on subjects with high redundancy in the data used to train it (such as Brexit, Miley Cyrus and Lord of the Rings) and obtains an acceptable result 50% of the time. However, the opposite is also true; the model struggles to generate a suitable result on specific and pointed subjects that are not very common in the data used to train it. So far nothing unusual.
Evaluated on different text comprehension, summary, reasoning and translation exercises, the model is ahead of the existing LMBC (Language Modeling of Broad Contexts - predicting the word following a sentence or paragraph) and CSR (Common Sense Reasoning - determining the meaning of an ambiguous pronoun) exercises. According to OpenAI, the model has not been trained in these specific areas.
The novelty from OpenAI, used to open-source its material, is that the team in charge of developing the GPT-2 algorithm decided not to disclose the source code, pointing at the dangerous aspect of the misuse of the tool for misinformation purposes. Leaving everyone in doubt about the actual performances of the tool.
The media success behind this OpenAI public statement lies on the one hand in the fact that the organization has refused, contrary to its habit, to make its most powerful version of the algorithm open source, and on the other that the examples of GPT-2 responses that have been made public have been shockingly realistic. This is the first time that an algorithm of this type has reached such a high level of writing skills. However, this success is reduced by much criticism from the Machine Learning community regarding the realism of GPT-2's responses.
Many community members have questioned the originality of the texts generated by the algorithm as being memorized and then restored and not "written" as such. Appendix 8.2 of the paper attached to the OpenAI GitHub publication discusses this point and suggests a possible memorization behavior of the tool. The authors thus show that the occurrence of word overlap rates between training data and GPT-2 responses are lower than between training and test data. In other words, this means that GPT-2 generates a text with fewer occurrences than a random set of WebText texts taken as test matter.

For the figure above, n-gram corresponds to a sequence close to n elements of a given sample of text. Most samples have less than 1% overlap, including over 30% of samples with no overlap, whereas the median for test set is 2.6% overlap.
The text generated by the algorithm (called "English-speaking Unicorns") has been inserted into the Turnitin plagiarism detector and yet it returns nothing conclusive. The story written by GPT-2 is not perfect and includes several inconsistencies but the final result is stunning and has been recognized by the Machine Learning community as consistent and of high quality for a language processing algorithm.
There are many reasons to doubt the quality of this model, especially since no one outside the OpenAI research team can test its performance. First, the subjective way in which OpenAI selected the performance examples of the model made public generates a lot of skeptical reactions. Second, the number of input injected into the model to obtain these results is also not known and would allow a better understanding of its actual performance. There are many grey areas leaving room for everyone to interpret the estimated performance of the model.
However, a lot of information has been provided by OpenAI and in particular a scientific article has been published with the GPT-2 results, which gives an idea of the intrinsic performance of the model. First, OpenAI provides a large number of test samples in its GitHub post. In addition, for each selected and published example with good performance, OpenAI indicates the number of tests that were necessary to obtain its results. This brings the GPT-2 publication to the same level as previous scientific publications in terms of quality in the field of language processing.

It is difficult not to take into account the advertising campaign and spectacular dimension that OpenAI has chosen in order to make its discovery known in the media. This can easily be seen from the catchy, end-of-the-world titles of articles that have been circulating on the web about the GPT-2 algorithm. OpenAI seems to be paying a lot of attention to its image and is trying, through GPT-2, to create a media event and get attention from the public. The fact that OpenAI directly solicited journalists to allow them to test the tool and write about it is proof of this.
It is important to remember that it is a non-profit association. The interest in this spotlight on OpenAI is obviously to obtain notoriety and legitimacy in order to collect more funding and expertise for its future research in the field of artificial intelligence. It is therefore in the association's interest that its discovery gets highly publicized and attract attention.
Even if OpenAI's choice not to disclose its algorithm looks like a marketing strategy move, it should not only be reduced to that. As may have been mentioned in various articles dealing with the OpenAI case, DeepMind, author of the famous AlphaGo Algorithm, could have made the same type of statement with the WaveNet algorithm, a high-performance speech generation tool. We can legitimately wonder about the danger that this technology could represent in the same way as GPT-2. When it was published, DeepMind chose not to focus on the danger that the misuse of their tool could represent and made it open-source like any other publication they had made in the past. The fact that OpenAI does not make its code public will not prevent the advent of a similar and more efficient technology. So why make this choice, if not to give public and private institutions the opportunity to have an appropriate response to the emergence of such technology?
OpenAI has succeeded in drawing the collective attention to the possible harmful use of advances in artificial intelligence research. This raises the debate on the limits of open-source in this field, as well as the impact that technological advances in artificial intelligence could have on our lives and how much responsibility it places on the various authors to secure their discoveries.
Artificial intelligence has a direct influence on our way of life because of its ease of access by anyone. It is therefore the responsibility of researchers, managers and other public or private actors to anticipate this type of problem before it occurs and thus lay the foundations for the healthy development of new information technologies.
If one thing is certain, it is that we need to step back and better understand the dimension and implications on our lives that the emergence of such a technology could have. The problem, because it has become one, is to be looked at in its entirety and it would seem that a step has been taken in terms of text generation via automated computer softwares. There are many applications and it must lead our governments to better consider the challenges involved in such technical advances, in order to escalate the fight against "FakeNews" and more particularly "DeepFakes" which could soon flood our news feeds.
The foundations of a debate have just been laid by OpenAI, the subject deserves to be taken seriously. If the performance of GPT-2 is proven, the consequences of a breakthrough in the field of language processing by artificial intelligence will directly affect our lives. Many jobs will be transformed and new possibilities will emerge (e.g. real-time multi-language translation AI and intelligent writing assistants). The future of artificial intelligence seems increasingly exciting and the possibilities are infinite, but it is also up to the main actors in each field to ask themselves the ethical questions involved in their technological advances and possibly to devote more time to these problems of combating their possible misuse. This technology is possible - OpenAI has just proven it to us through GPT-2. We must now find ways to counter the abuse of these tools, which we know will soon be available to everyone.
If you also want to test the capabilities of the light version of the algorithm called "117M", a developer has made the program available to everyone on a web address.
Here is the link to the askskynet site.
And the associated article: I have created a website to query the GPT-2 OpenAI model (AskSkynet.com)
If you want to know more about our AI solutions, check out our Heka website



{kind=link}