Canadian Hydrogen Observatory: Insights to fuel…

How to understand Machine Learning models and make them more human interpretable ?
With the increase of computing power and large datasets, Machine Learning and Deep Learning have slowly begun to widespread in most industries during the past few years. Whereas new performant algorithms appear quite regularly, the standard toolbox often remains the same, relying on traditional but more transparent models (linear or tree-based). In a Latin business context, a model not understandable will be considered as risky and will hardly be used. Thus, interpretability could be a way to close the gap with the Anglo-Saxon culture of risk management. Being able to answer the questions “Why should I trust your model?” and “How does it take its decisions?” is key to:
In a Machine Learning context, interpretability is the faculty to explain a model’s predictions to a human. It is a wide definition, as “human” includes the expert data scientist as well as the perfect beginner. Hence, interpretability equally concerns black box models, white box ones, and even hybrid approaches such as expert aggregation.

Notional Explainability versus Prediciton accuracy for several models
Consequently, there are different ways to perform this interpretation. Whether the model is naturally understandable (intrinsic) or needs post treatment (post-hoc), if the interpretation methods focuses on a given prediction (local) or on the full dataset (global), and finally if this method is linked to the model (model-specific) or can be applied to any model (model-agnostic).
Of course, several processes already provide insights on machine learning models comprehension. They can be grouped under Exploratory analysis and visualization techniques (clustering, dimensionality reduction, …) and Model performance evaluation metric (accuracy, ROC curve, AUC, RMSE, …). But these techniques are more focused on data, features and model selection than really building a human interpretable picture of a model. They would not be enough to explain precisely why a model’s performance decreases over time, nor to identify the blind spots of a model. Moreover, they are often too abstract whereas business stakeholders might need more human-interpretable interpretation (HII).
We present in the further sections three model interpretation approaches that provide more fairness, consistency and transparency. They all are model-agnostic and only require predictions from the black box model.

Overview of the three interpretation methods. This is only a summary, the benefits and drawbacks of each method may vary depending on the problem studied.
The global surrogate method is a global one. It consists in fitting an interpretable model (usually tree-based) to the black box predictions and then draw the decision-making policy by interpreting this surrogate model. Understand a machine learning model with more machine learning! This approach is very intuitive, flexible and handy, but seems to only shift the performance vs interpretability issue from the original model to the surrogate one.
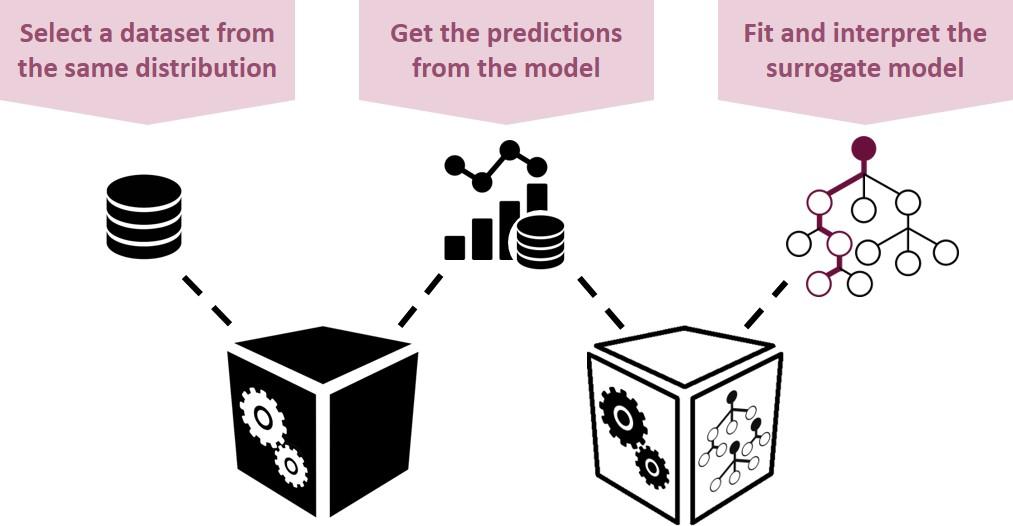
The global surrogate method
LIME, for Local Interpretable Model-agnostic Explanations, also rely on a surrogate model, but at a local scale this time. It generates a weighted dataset from a given prediction using the black box and approximates it with a linear, and thus interpretable, model. This idea is easily adaptable to all kinds of problems (NLP, Computer Vision) and gives simple interpretation. However, the neighborhood definition can be a critical issue depending on the feature space, leading to some instability in the results.

Finally, the Shapley Values method is a very trending local approach based on game theory. It quantifies which part of a profit earned by a team each player must expect. For our model, the players correspond to the different features and the gain to the prediction. So, computing all the coalitions earnings with and without a given feature will allow to measure its impact on this prediction, which is the Shapley Value. This is the only explanation method relying on a solid theory and thus considered as fair and consistent, accounting for its success. It requires a lot of computing time, but can be fastened by Monte-Carlo sampling, and combined with other methods to produce powerful interpretation for all types of problems.
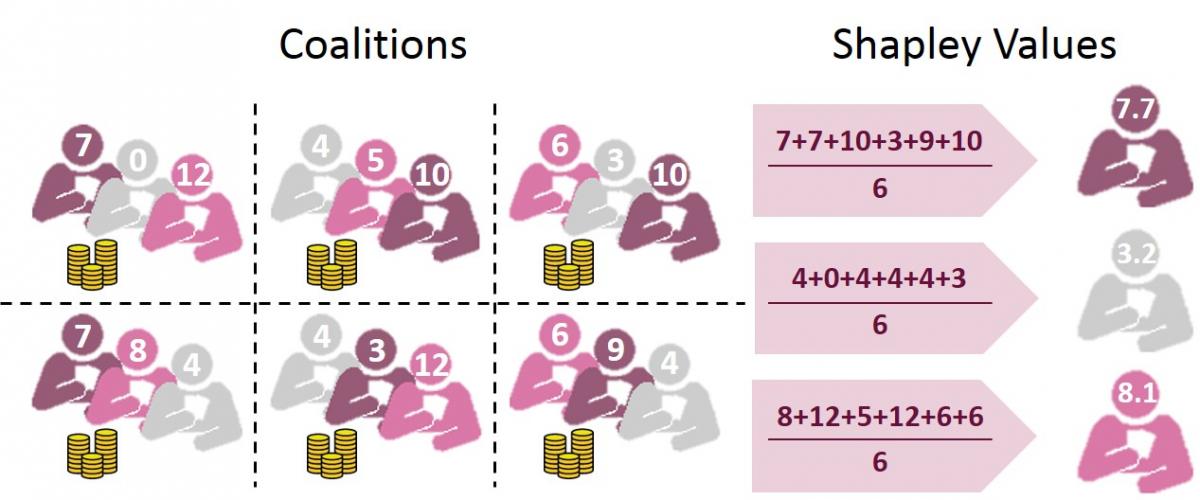
Shapley values computing example
Although these few methods and their applications represent huge breakthrough in Machine Learning comprehension, they are quite recent. Shapley Values, although already used in marketing attribution or airport management for example, still need to be sped up to be fully scalable to all models. Interpretable Machine Learning is only in its early stages.
Sources:
[i] Interpretable Machine Learning book
[ii] Library for Shapley Values in python
[iii] Library for LIME and other methods in python
If you want to know more about our AI solutions, check out our Heka website
Contact : david.martineau@sia-partners.com

