Canadian Hydrogen Observatory: Insights to fuel…

What are the obstacles to the Industrialization of Data Science projects ? Convictions and feedback
Data Science has emerged in companies over the last ten years, partly due to increasing volume of valuable data available. One key figure measures this phenomenon: more than 90% of the world's data has been created in the last two years. This explosion of data holds many new business opportunities, provided a structured organization is set up.
For 5 years now Sia Partners has been investing in a team fully dedicated to applying Data Science skills to our clients' business problems. These experiences have enabled us to draw two conclusions: Data Science initiatives have multiplied but only a small number of them have reached industrialization.
This two-fold observation has led us to understand the challenges to the industrialization of Data Science projects and establish good practices in order to overcome them.
We addressed this topic during the December session of the AI&Society conference in Paris in order to share our convictions and experience with an audience that is increasingly interested and aware of these issues.
The Proof of Concept (POC) is a small project intended to experiment a use case. Its purpose is to explore several solutions and provide concrete proof of their feasibility and effectiveness.
Used upstream of a larger project, the POC allows to federate around an idea and to quickly bring it to fruition within a limited perimeter.
It must also bring the different actors of a project to :
Data Science is a new field for many stakeholders, of great technical complexity and in perpetual technological evolution. Moreover, it is a transversal field bringing together many actors with various profiles.
In this context, the POC is a preliminary stage in the realisation of a Data Science project that is essential and particularly well suited.
This step is essential in order to embark business teams with little theoretical knowledge on the subject. It allows them to test a reduced but concrete version of the tool, to provide feedback to the Data Science teams and to agree together on the adjustments to be made to the developed prototype.
Beyond its experimental nature, its interest as a demonstrator and a decision support tool, the POC encourages the sharing and dissemination of a Data Science culture within a department or company.
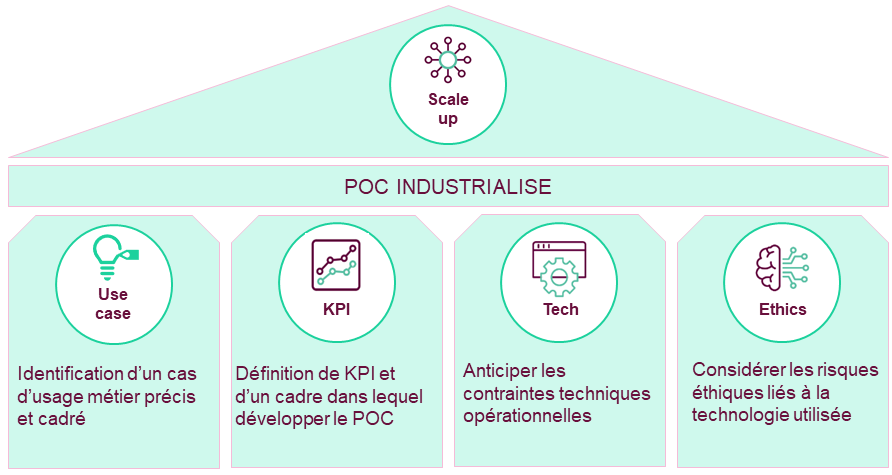
The four pillars of a successful POC
Over the past 5 years, we have had the opportunity to develop many Data Science POCs for our clients from various industries.
These experiences have allowed us to acquire convictions as to the essential elements to be guaranteed or put in place to maximize the benefits of this preliminary step:
In this respect, we offer our clients, with our Compliance department, a framework and tools for assessing the ethical risk inherent in AI projects, its remediation, as well as suggestions and guidelines on the governance to be put in place to ensure that the individual, social, societal and environmental impact of AI-related applications are taken into account.
When this preliminary phase of POC is successful, it is essential to consider the generalization and production of the identified use case. However, we have noticed that the industrialization stage of Data Science projects faces significant obstacles.
What are the obstacles to the industrialization of a Data Science POC?
As mentioned previously, we are convinced that the success of a Data Science project necessarily requires the clear definition of a business use case. It must also be at the core of industrialization issues. All constraints, including technical ones, must be approached through the prism of the business need.
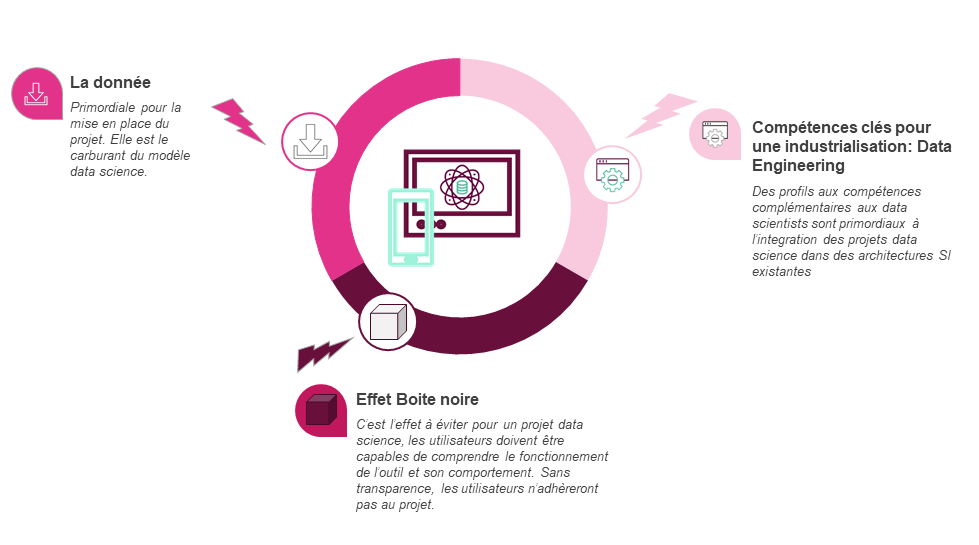
We have listed below the main challenges to the industrialization of this type of project and and how to overcome them:
Data is essential in setting up a Data Science project. It will be the determining factor in the quality of the models developed. It is therefore fundamental to have good quality data and that it is available in an operational environment to feed the models of a Data Science project.
In many cases, we have observed a significant gap between the quality of the data used during the POC phase and that used in operational conditions.
In this industrialization stage, it will therefore be necessary to set up adequate data flows as well as test and monitoring systems to guarantee the quality of the data.
Also, as mentioned above, a Data Science project can and must be an opportunity to disseminate the Data culture in companies. When it is a success, it is important to promote it by making it a reference project in its field and by exploiting its results.
To do this, we promote the use of API technology that allows to centralize, standardize, document and secure access to data. In this way, the data and results of a successful Data Science project can be reused by other users and new use cases can emerge. The use of the API also facilitates exchanges between the different information system building blocks of a company.
The users of a Data Science project are the sponsors who guarantee the coherence of the tool and its functionalities. It is therefore fundamental for the adoption of the tool that they adhere to its development and the methodologies implemented.
Machine Learning (and Deep Learning) models are technically complex models that present a significant black box effect for their users. This is often a significant obstacle to their adoption.
On the one hand, the interpretability of the models will have to be made easier :
On the other hand, the future users of the tool must be "on-boarded" from the definition stage of the project and throughout the development process. In this way, they are actors of the development of the tool. The Agile method, by its organization in short and regular sprints punctuated by "demos", is a methodology particularly adapted to co-constructing a Data Science project between the project team and business users.

Over the last 10 years, major investments have been made in the field of Data Science, both in terms of tools and skills, which have enabled the emergence of many innovative POCs with high business value added.
However, due to their complexity, Data Science projects have technical specificities (calibration, validation and estimation of models in particular) which make their integration into an existing IS system more complex. It is therefore necessary to acquire skills and to set up tools adapted to these particular constraints: Data Engineering.

That is why over the past year, we have set up a team of Data Engineers and developed a Data Science platform: Heka. This team and this tool allow us, on the one hand, to quickly (in a few minutes) provide our Data Scientists with development environments for the realization of POCs. On the other hand, thanks to the technological choices that have been made (Cloud, Kubernetes, Docker in particular), we are able to put into production almost instantaneously the projects thus developed, either within our environments or those of our clients.
We are convinced that strengthening of Data Engineering's skills is and will be at the core of the development of Data Science projects.
Contact : david.martineau@sia-partners.com

