Canadian Hydrogen Observatory: Insights to fuel…

Our use case was to be able to detect PII information in PDF documents and anonymize them.

Our use case was to be able to detect PII information in PDF documents and anonymize them. We needed OCR and NLP capabilities. We have developed a quick POC using Amazon Textract and Amazon Comprehend. We made a Jupyter Notebook but quickly we switched to a Streamlit web app. We benchmarked several models including open source models.
Our ML pipeline consists of 4 stages: preprocessing, OCR, NER, and post-processing.
This project comes from one of our Stratumn solution customers: Axa Global Reinsurance. Stratumn is a product that enables complex business processes to be managed while ensuring high traceability of exchanges via the blockchain.
AGRe uses Stratumn mainly for Technical Accounting and Renewal Pack workflows. Both require documents to be uploaded. AGRe must comply with GPDR and sure that no personal nor confidential data are uploaded to the platform. They use Adobe to analyse PDF documents, but it is mainly a manual job that is time-consuming, and error-prone with low value added to human operators.
We discussed with them the integration of a document anonymization solution into Stratumn, which could be used when a document is uploaded. This solution would be based on AI/ML bricks to offer an initial detection of personal data with a proposed anonymization mask, then hand over to the end-user, who would be able to modify the anonimized elements as well as validate. The mask is then applied to the document and uploaded to Stratumn.
Data is provided directly by the end user through the Stratumn interface. In order to achieve this, we need OCR and NLP models (the NLP requires NER and PII capabilities). Two main criteria were considered: accuracy and response time. Because it's a synchronous application, it was not possible to keep the end user waiting too long. The accuracy was mitigated by the end-user validation. Even detecting 80% of PII in a document was an improvement for them. Model hosting was also part of the decision.
In designing the solution, we had to take several parameters into account: template serving and performance management in the case of a voluminous document. For template serving, OCR templates (notably open source such as Tesseract) require GPUs to deliver acceptable performance. The option of running templates 24/7 was not an option for cost reasons. We needed a solution to have the model on demand. Several options were available: use Knative to serve the model (with a cold start for the first API call), leverage Sagemaker capabilities to host a Tesseract model or use a managed service (Amazon Textract).
Hosting the model was not the only constraint, as was maintaining and updating it. For the first implementation of this solution, we decided to use AWS-managed services (Amazon Textract and Amazon Comprehend), but to create an OCR and NLP interface in our architecture design so that we could integrate other models (either open source or specific models for business use cases).
To process a document with many pages, we decided to adopt a "stream" approach, using solutions such as Kafka. Returning to the original use case, the document is uploaded via the platform, and the end-user waits for a response from the server. It's not necessary to have finished processing the entire document to give the client initial feedback. We have therefore separated the pages of the document in order to process them individually.
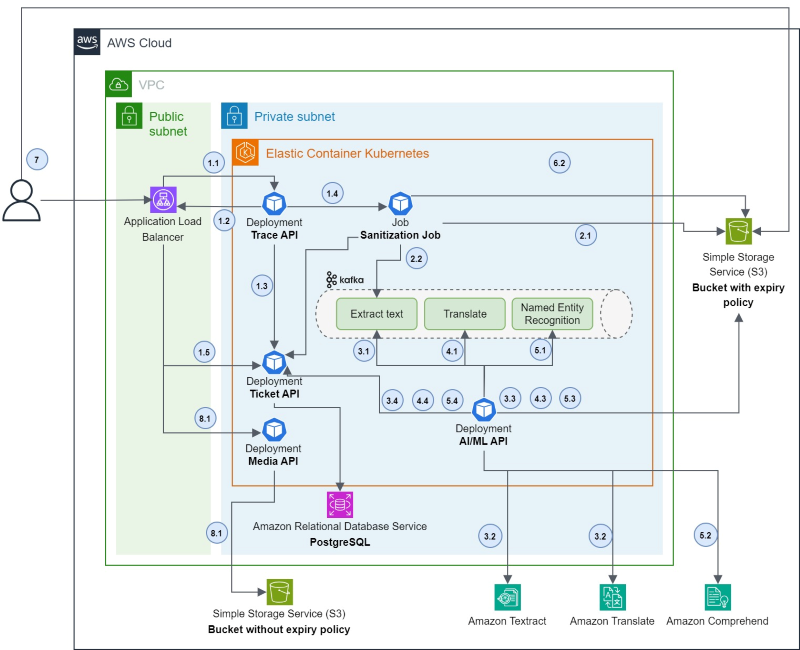
1.1 Upload the image to Trace API.
1.2 Trace API calls Ticket API to create a ticket.
1.3 The frontend uses the ticket to inspect the status of the process until it's finished.
1.4 Trace API triggers the creation of a Sanitization Job.
1.5 The user retrieves Ticket API.
2.1 The Sanitization Job splits the document into a list of images and uploads them to a bucket with an expiry policy.
2.2 The Sanitization Job sends one message per page to the first step topic with metadata containing the full process chain (extract text, translate, and NER).
3.1 AI/ML API pulls a message from the topic.
3.2 AI/ML API downloads the image data from the bucket and calls Amazon Textract.
3.3 AI/ML API pushes the results to the bucket and sends a new message to Kafka to perform the translation task.
3.4 AI/ML API updates the status of the ticket to provide information to the frontend.
4.1 AI/ML API pulls a message from the topic.
4.2 AI/ML API downloads the image data from the bucket and calls Amazon Translate.
4.3 AI/ML API pushes the results to the bucket and sends a new message to Kafka to perform the NER task.
4.4 AI/ML API updates the status of the ticket to provide information to the frontend.
5.1 AI/ML API pulls a message from the topic.
5.2 AI/ML API downloads the image data from the bucket and calls Amazon Comprehend.
5.3 AI/ML API pushes the results to the bucket.
5.4 AI/ML API updates the status of the ticket to provide information to the frontend.
6.1 The task continuously checks the ticket's status and waits for "Pipeline done".
6.2 The task downloads the artifacts, creates the JSON that will be read by the frontend, and uploads it to S3. Finally, the task updates the ticket with the status "Done".
7 Once the status is set as "Done," the frontend downloads the JSON containing word boxes and private information presence. Then the frontend displays the information to the end user with the document and the bounding boxes. The human validation can start with the document. The user is asked to verify the Al prediction and adjust content that needs to be sanitized.
8.1 The frontend pushes the sanitized document to Media API.
8.1 Media API encrypts and stores the file in a persistent bucket.


