Benchmark des Plateformes de Gestion de la…

Depuis une décennie, des avancées prodigieuses ont été réalisées dans le traitement automatique du langage, nos experts en datascience Sia Partners vous en dévoilent le fonctionnement et discutent de leur portée.
Le NLP (Natural Language Processing ou Traitement Automatique du Langage en français) est l’un des domaines les plus actifs de la Data Science sur la décennie écoulée. De nombreux modèles sont développés et publiés régulièrement par les GAFAM ou autres laboratoires de recherche.
Ces modèles sont souvent plus performants que leurs prédécesseurs dans la plupart des tâches linguistiques grâce à un algorithme différent, une base d’apprentissage plus conséquente ou un objectif primaire d’apprentissage revisité.
En Novembre 2018, Google AI (département de R&D sur l’Intelligence Artificielle de Google) a rendu public le modèle BERT qui a révolutionné le NLP, aiguillé la marche à suivre pour les futurs modèles et sert aujourd’hui de base de comparaison aux nouveaux travaux.
Grâce aux travaux de R&D de Sia Partners sur les sujets novateurs de Data Science, des projets concrets se matérialisent. Ces réalisations industrielles, dont nous détaillerons certaines par la suite, à la pointe des dernières innovations, peuvent par exemple prendre la forme de voicebot, d’outils d’analyse de commentaires, de détection de fraudes.

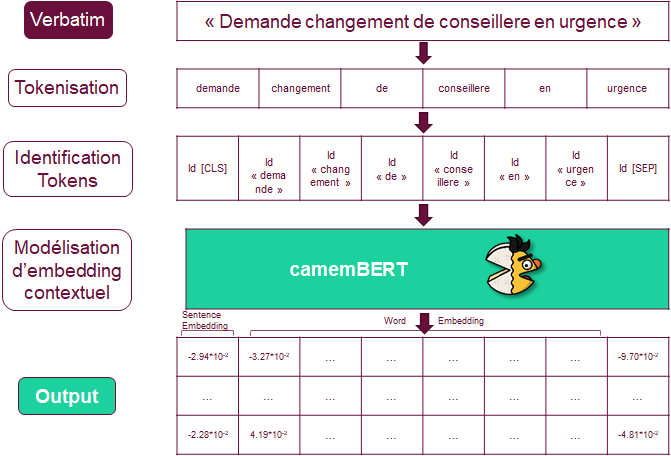
Avant d'expliquer son fonctionnement, il est important de comprendre que BERT est un modèle d’embedding, c’est à dire qu’il permet, grâce à l’entraînement d’un réseau de neurone, de représenter du texte (mots ou phrases) sous forme de vecteur numérique en fonction du contexte. Cette représentation permet ensuite d’être utilisée plus facilement par une machine et en particulier par les algorithmes de Machine Learning que nous mettons en place.
BERT est l’acronyme de Bidirectional Encoder Representations for Transformer. Pour essayer d’y voir plus clair nous allons expliquer simplement les concepts clefs derrière cet outil de représentation linguistique.
Bidirectional indique que le modèle va travailler dans les deux sens d’une phrase. Une lecture classique par un humain se fait dans un seul sens (gauche à droite, droite à gauche ou haut en bas) donc les modèles linguistiques ont dans la grande majorité été créés de la même manière. C’est-à-dire souvent en cherchant à prédire le mot suivant à partir du début de la phrase. BERT s’émancipe de cette idée en s’autorisant la lecture dans les deux sens. Illogique d’un point de vue humain, - prévoir un mot à partir du mot suivant -, cela fait sens pour un algorithme qui cherche à définir le sens de mots dans le contexte de la phrase le contenant. Pour atteindre cet objectif, le modèle de Google masque une proportion des mots de la phrase à l’algorithme pour que celui-ci essaye de le prédire. Cela va permettre d’avoir un grand nombre de données car n’importe quelle phrase peut servir à l’apprentissage de BERT. Des phrases labellisées ne sont plus directement nécessaires pour entraîner un modèle “contextualisé”.
Encoder Représentations définit ce qui est la base des modèles de NLP. A savoir représenter une donnée textuelle d’une manière simple pour l’ordinateur et permettant des modifications généralisées. Cette partie est également appelée embedding (imbrication en français), elle va servir à représenter un objet textuel (mot, phrase, paragraphe, document, etc.) numériquement à l’aide d’un vecteur. Dans le cas de BERT, cet embedding est fait sur l’ensemble des mots (word embedding) d’une phrase et sur la phrase elle même (sentence embedding) à l’aide d’un vecteur numérique normalisé de 768 valeurs. Grâce à l’aspect bi-directionnel de l’apprentissage du modèle, chaque mot représenté vectoriellement contiendra une définition du mot au sein du contexte de la phrase. Pour exemple, dans les phrases « Steve Jobs eats an apple » et « Steve Jobs created Apple », les mots “apple”, bien que orthographiés de manière identique ont un sens différent. BERT va permettre de saisir cette particularité et construira des vecteurs distincts entre les deux pommes. Cette représentation contextualisée des mots est un changement fort par rapport aux représentations numériques plus classiques (et plus connues) que proposait le NLP.
Enfin le Transformer est le cœur du modèle BERT. Il représente la partie purement technique du modèle et nous essaierons de l’expliquer simplement. Un Transformer est une succession de réseaux neuronaux appelé couches d’attention. Ces couches (existant sous la forme Encoder et Decoder) servent à retenir les points d’attention de la phrase que l’on cherche à numériser. Par exemple, dans la phrase « Le boulanger mange le pain car il est bon », le pronom personnel « il » se rapporte au pain et non au boulanger. Les couches d’attention vont permettre de capter ce lien et de construire des vecteurs de mots contenant ce lien. Le Transformer va ainsi produire en sortie de l’ensemble des couches l’embedding de chaque mot de la phrase ainsi que l’embedding de la phrase elle-même.

Par ailleurs, BERT poursuit un second objectif qui n’est pas explicité dans l’acronyme. Il s’agit du Next Sentence Prediction (NSP), dont le but est de qualifier le lien qui peut exister entre deux phrases. Pour la phase d’entraînement, deux phrases sont proposées à BERT qui doit déterminer si la seconde est la suite de la première (une question et sa réponse par exemple). L’inconvénient de cette tâche est qu’elle nécessite un jeu de données plus complexe à obtenir (un échantillon de deux phrases consécutives, un échantillon de deux phrases indépendantes).
Pour récapituler, BERT a donc l’avantage de représenter du langage (mot ou phrase) numériquement en conservant le contexte. Son second avantage est d’avoir facilité l’apprentissage en ayant besoin de phrases basiques dans lesquelles certains mots seront masqués puis prédits et de couples de phrases consécutives ou indépendantes.
A l’été 2019, Facebook AI a développé le modèle RoBERTa (Ro pour Robustly optimized) qui reprend dans les grandes lignes le modèle BERT en apportant quelques modifications.
Ces modifications se retrouvent principalement dans les hyperparamètres d’apprentissage du modèle (taille des batch, taux d’apprentissage, taille du jeu de données) mais le changement principal est la suppression de l’objectif de NSP. Ainsi RoBERTa se spécialise uniquement sur la tâche d’encoder contextuellement un objet linguistique. Cette légère variation permet au modèle d’obtenir de meilleurs résultats que son prédécesseur BERT dans de nombreux domaines liés langage. Par contre la suppression de l’objectif NSP va décroître les performances sur des tâches clefs, telles que la détection d'intentions.
BERT a été conçu pour une utilisation uniquement sur le langage anglais. Mais son principe de construction et d’apprentissage est entièrement transférable à d’autres langues à condition de disposer de suffisamment de données.
En Octobre 2019, Facebook, en partenariat avec l’INRIA, a développé CamemBERT. Ce modèle n’est autre que le modèle RoBERTa transposé au français et qui a été entraîné sur le jeu de données français d’Oscar (Open Super-large Crawled ALMAnaCH coRpus) représentant 138 go, soit plus de 23 milliards de mots. Il en ressort un outil très performant dans les tâches linguistiques comparativement aux modèles multilingues fréquemment utilisés pour le français.
Sia Partners possédant une expertise forte dans les domaines d’intelligence artificielle, CamemBERT fait partie des outils apportant une véritable nouveauté pour les sujets français. Ce modèle linguistique (ou d’autres très similaires) est donc utilisé dans de nombreux cas d’usages de valorisation de donnée textuelle.
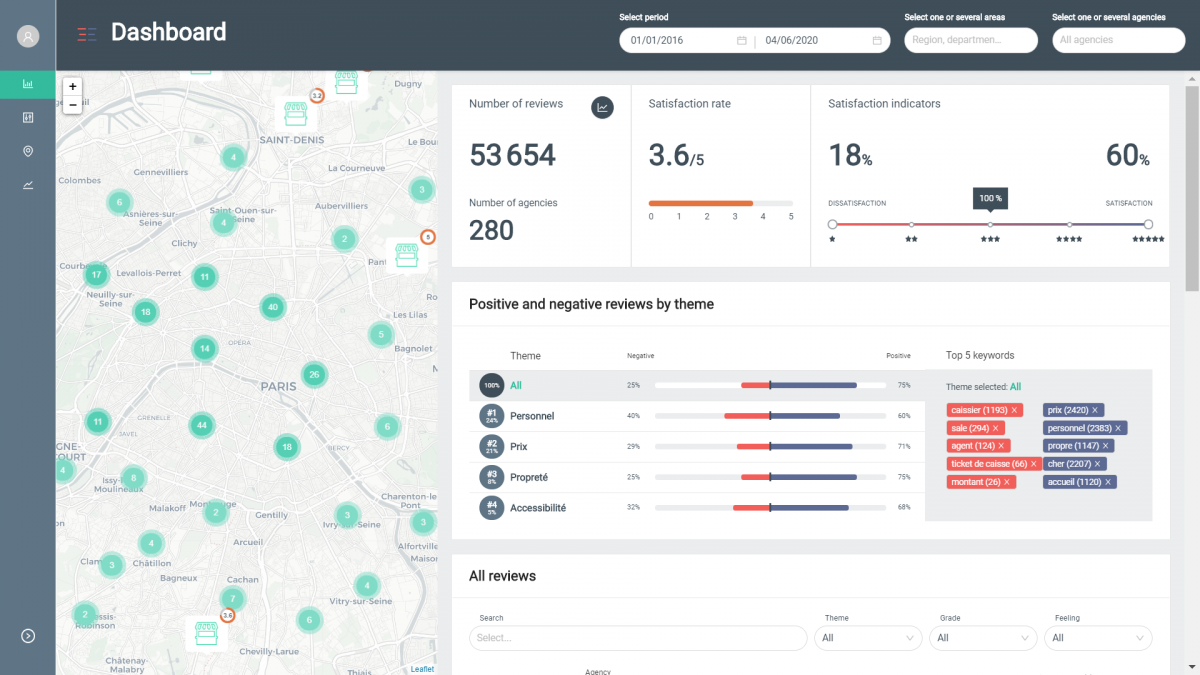
La solution Deep review développée par Sia Partners repose sur une idée simple : évaluer le ressenti d’usagers au travers des commentaires déposés sur des sites en ligne ou via des baromètres de satisfaction internes. L’analyse manuelle de ces retours textuels, dont le nombre évolue exponentiellement, est souvent coûteuse en temps et ne permet pas d’avoir des indicateurs “intelligents” d’aide à la décision pour les équipes marketing et opérationnelles.
C’est ici que BERT et le NLP en général apporte la plus-value dont Sia Partners dispose. Nos équipes Data Science ont en effet construit des algorithmes permettant d’effectuer différentes tâches de compréhension du langage afin de restituer et synthétiser le contenu des commentaires analysés.
Le produit Deep Review dispose d’un outil d’analyse de sentiments. C’est-à-dire qu’il capable de retrouver la positivité (ou négativité) d’une phrase. Ici BERT va servir pour numériser les commentaires. Les vecteurs vont ensuite servir pour créer un modèle de classification (réseau de neurones, forêt aléatoire, ou autre) entre négatif, neutre ou positif.
De nombreuses données sont nécessaires pour obtenir un outil suffisamment performant. Ces données doivent en plus être labellisées entre les trois classes finales (négatif, neutre, positif) et dans des proportions équivalentes pour éviter les biais.
Au final, après entraînement de notre modèle sur plusieurs centaines de milliers de commentaires, le classifieur catégorise correctement les données dans 95% des cas. Un outil aussi performant permet une analyse poussée sur l’analyse des sentiments.
Cette analyse de sentiments est ensuite couplée à une analyse thématique permettant ainsi de comprendre pour chaque commentaire les thèmes mentionnés et la satisfaction ou insatisfaction associée.
Ces résultats permettent ainsi d’avoir des indicateurs clés pour l’utilisateur pour mieux comprendre son réseau de points de vente ou ses produits, avec notamment les fonctionnalités principales suivantes :
Un deuxième use case fréquemment rencontré chez Sia Partners est celui de la détection d’intentions. Contrairement à l’analyse de sentiments, l’objectif de la détection d’intentions est plus complexe. On ne cherche pas à classifier un objet linguistique (mot, phrase) entre trois catégories mais entre un très grand nombre (dix, cent, parfois plus) et parfois sans les avoir définis à l’avance. Pour atteindre cet objectif, les moyens sont aussi plus difficiles à construire.
Par exemple, une des solutions possibles pour la détection d’intentions est de construire une base labellisée d’exemples d’objets linguistiques se rapportant à une intention. On rapproche ensuite la phrase cible vers une des intentions.
Comme dit plus haut, ce modèle est construit avec l’objectif de prévoir les mots manquants d’une phrase. Malgré les nombreuses qualités des modèles BERT, la comparaison entre deux phrases débouche assez souvent sur des incohérences et des résultats faibles par rapport à d’autres modèles.
Pour pallier cette difficulté, il convient de spécialiser le modèle BERT. On utilise alors des réseaux neuronaux siamois pour se spécialiser dans les tâches de NLI (Natural Language Inference).
Le NLI est la comparaison de deux phrases et le rapport qui les lie. La phrase A et la phrase B peuvent être neutres, parler du même sujet avec un avis similaire ou bien parler du même sujet avec un avis opposé. A partir de ces trois possibilités de lien entre les phrases il est possible de spécialiser un modèle BERT pour que la vectorisation numérique qu’il crée conserve les premiers acquis (définition et contexte) et qu’en plus cette représentation puisse être comparée à une autre avec la capacité d’obtenir le rapport quantifié qui les lie. Une valeur positive indiquerait un lien existant et positif, une valeur négative un lien existant mais opposé et une valeur nulle l’absence de lien.
Ainsi, la détection d’intentions peut se faire en rapprochant la phrase cible d’une intention soit avec des liens de valeurs positives (on rapproche à l’intention qui traite du même sujet et avec la même polarité) ou bien avec des liens de valeurs absolues positives (on rapproche à l’intention qui traite du même sujet).
Un cas d’usage existant et rencontré par Sia Partners pour cette problématique a été la construction d’un agent conversationnel. Le but du projet était de construire un algorithme capable de répondre aux appels d’un utilisateur et de fournir les réponses adéquates aux questions posées. La détection d’intentions rentrait en compte lorsqu’un appelant pose une question. Il faut alors que l’outil rapproche la question posée d’une intention préalablement enregistrée dans une base de référence. Si une intention est détectée l’agent conversationnel peut alors fournir la réponse adéquate.
En utilisant cette même spécialisation des modèles BERT, une autre solution possible pour faire de la détection d’intention est de faire du clustering (rapprochement). C’est-à-dire de rapprocher les phrases entre elles selon leur sensibilité. L’avantage est qu’il n’y a plus besoin de construire de base d’intentions à la main. L’inconvénient est que le rapprochement entre les phrases peut produire des résultats difficilement interprétable.

BERT a donc popularisé l’utilisation fréquente de Transformers dans les modèles linguistiques. C’est aujourd’hui un modèle de référence utilisé dans de nombreux domaines de NLP. Sia Partners a su développer grâce à son expertise data des solutions innovantes basées sur cette technologie comme l’analyse de sentiments et la détection d'intentions présentées plus haut. Aujourd’hui, avec l’avancée de ces modèles linguistiques, et d’autres modèles tel que GPT-2 d’OpenAI (groupe Tesla) capable de construire du contenu linguistique réaliste (réponse, description, biographie, etc.) à partir de données structurées, de nouvelles perspectives vont se créer et de nombreux projets vont pouvoir prendre forme en machine learning.

