Observatoire Canadien de l'Hydrogène : observer,…

Quels sont les freins à l’industrialisation d’un projet Data Science ? Convictions et retours d’expérience
Cela fait maintenant une dizaine d’années que la Data Science a émergé au sein des entreprises suite à l’explosion du volume de données valorisables notamment. Un chiffre en donne la mesure : plus de 90% des données mondiales ont été créées ces deux dernières années. Cette explosion promet de nombreuses nouvelles opportunités business à condition d’adopter une organisation adaptée.
Depuis maintenant 5 ans, Sia Partners investit massivement dans une équipe intégralement dédiée à l’application de compétences Data Science aux problématiques business de nos clients. Ces années nous ont permis d’effectuer un double constat : les initiatives Data Science se sont multipliées mais seule une faible partie d’entre elles arrivent à un stade industrialisé.
Ce double constat nous a amené d’une part à comprendre les freins à l’industrialisation des projets Data Science et d’autre part à instaurer des bonnes pratiques à respecter pour les contourner.
Nous sommes intervenus sur ce sujet lors de la session du mois de décembre de la conférence AI&Society afin de partager nos convictions et notre expérience face à un public toujours plus intéressé et averti sur ces questions.
Le Proof of Concept – POC (en français : « Preuve de concept »), est un projet de taille réduite servant à expérimenter un cas d’usage. Il a pour objectif de creuser plusieurs solutions et d’apporter une preuve concrète de leur faisabilité et de leur efficacité.
Utilisé en amont d’un projet plus large, le POC permet de fédérer autour d’une idée et de la concrétiser rapidement sur un périmètre restreint.
Il doit par ailleurs amener les différents acteurs d’un projet à :
La Data Science est un domaine nouveau pour de nombreux acteurs, d’une complexité technique importante et en perpétuelle évolution technologique. De plus, il s’agit d’un domaine transverse rassemblant de nombreux acteurs aux profils variés.
Dans ce contexte, le POC est une étape préliminaire à la réalisation d’un projet Data Science particulièrement adaptée et nécessaire.
Cette étape est primordiale afin d’embarquer des métiers n’ayant que peu de connaissances théoriques sur le sujet. Elle leur permet de tester une version réduite mais concrète de l’outil, de donner leurs retours aux équipes Data Science et de convenir ensemble des ajustements à apporter au prototype développé.
Au delà de son caractère expérimental, de son intérêt en tant que démonstrateur et d’outil d’aide à la décision ; le POC favorise donc le partage et la diffusion d’une culture Data Science au sein d’un département ou d’une entreprise.

Les quatre piliers de succès d'un POC
Au cours des 5 dernières années, nous avons eu l’occasion de développer de nombreux POCs Data Science pour nos différents clients provenant de tout type d’industrie.
Ces expériences nous ont permis d’acquérir des convictions quant aux éléments primordiaux à garantir ou mettre en place pour maximiser les avantages de cette étape préliminaire :
En cela, nous proposons à nos clients, avec notre département Compliance, un cadre et des outils permettant l’évaluation du risque éthique inhérent aux projets d’IA, sa remédiation, ainsi que des pistes de réflexion autour de la gouvernance à mettre en place pour garantir la prise en compte de l’impact individuel, social, sociétal et environnemental des évolutions liées à l’IA.
Lorsque cette phase préliminaire de POC est un succès, il convient d’envisager la généralisation et la mise en production du cas d’usage identifié. Cependant, nous avons observé que cette phase d’industrialisation de projets Data Science faisait face à d’importants obstacles.
Comme évoqué précédemment, nous sommes convaincus que la réussite d’un projet Data Science passe nécessairement par la définition d’un cas d’usage business. Il doit également être au coeur des problématiques d’industrialisation. Toutes les contraintes, y compris techniques, doivent être abordées à travers le prisme du besoin métier.
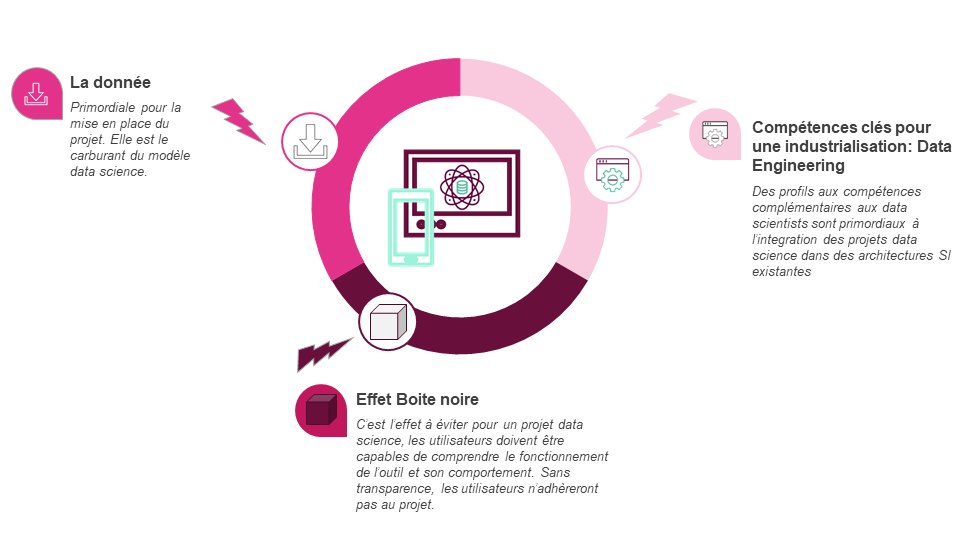
Nous avons listé ci-dessous les principaux freins à l’industrialisation de ce type de projet et partageons quelques clés pour les contourner :
La donnée est primordiale dans la mise en place d’un projet Data Science. Elle sera le facteur déterminant de la qualité des modèles développés. Il est donc fondamental qu’elle soit de bonne qualité et disponible en conditions opérationnelles pour alimenter les modèles d’un projet Data Science.
Dans de nombreux cas, nous avons observé un écart trop important entre la qualité des données utilisées lors de la phase de POC de celles utilisées en conditions opérationnelles.
Dans cette phase d'industrialisation, il conviendra donc de mettre en place les flux de données adéquats et des dispositifs de test et de monitoring permettant d’en garantir la qualité.
Aussi, comme évoqué précédemment, un projet Data Science peut et doit être une opportunité de diffusion de la culture Data en entreprise. Lorsqu’il est un succès, il est important de le promouvoir en en faisant un projet référent dans son domaine et en permettant d’en exploiter les résultats.
Pour cela, nous promouvons l’usage de la technologie API qui permet de centraliser, normaliser, documenter et sécuriser l’accès à la donnée. Ainsi, les données et les résultats d’un projet Data Science à succès pourront être réutilisés par d’autres utilisateurs et faire émerger de nouveaux cas d’usage. L’usage de l’API facilite également les échanges entre les différentes briques SI d’une entreprise.
Les utilisateurs métiers d’un projet Data Science sont les garants de la cohérence de l’outil et des fonctionnalités qui le composent. Il est donc fondamental pour l’adoption de l’outil que ceux-ci adhèrent à son développement et aux méthodologies mises en place.
Les modèles de Machine Learning (et de Deep Learning) sont des modèles complexes d’un point de vue technique qui présentent un effet boîte noire important pour leurs utilisateurs. Cela se révèle être un obstacle fort à leur adoption.
Il conviendra d’une part de faciliter l’interprétabilité des modèles :
D’autre part, les futurs utilisateurs de l’outil doivent d’être “embarqués” dès la phase de cadrage et tout au long du développement. De cette manière, ils sont acteurs du développement de l’outil. La méthode Agile, par son organisation en sprints courts et réguliers ponctués de “démo”, est une méthodologie particulièrement adaptée pour co-construire un projet Data Science entre équipe projet et utilisateurs métiers.

Au cours des 10 dernières années, des investissements majeurs ont été réalisés dans le domaine de la Data Science, à la fois en termes d’outils et de compétences, ce qui a permis l’émergence de nombreux POCs innovants et à forte valeur ajoutée business.
Cependant, par leur complexité, les projets Data Science présentent des spécificités techniques (calibration, validation et estimation de modèles notamment) qui complexifient leur intégration dans un système SI existant. Il est donc nécessaire d’acquérir des compétences et de mettre en place des outils adaptés à ces contraintes particulières : le Data Engineering.

C’est pourquoi, depuis un an, nous avons constitué une équipe de Data Engineers et investi dans le développement d’une plateforme Data Science : Heka. Cette équipe et cet outil nous permettent, d’une part, de mettre rapidement (en quelques minutes) à disposition de nos Data Scientists des environnements de développement pour la réalisation de POCs. D’autre part, grâce aux choix technologiques qui ont été faits (Cloud, Kubernetes, Docker notamment), nous sommes en mesure de mettre en production quasi-instantanément les projets ainsi développés, que ce soit au sein de nos environnements ou ceux de nos clients.
Nous sommes convaincus que l’accès aux compétences de Data Engineering est et sera l’enjeu au coeur du développement des projets Data Science.
Si vous souhaitez en savoir plus sur nos solutions d'IA, rendez-vous sur notre site web Heka


