Observatoire Canadien de l'Hydrogène : observer,…

Application d’un algorithme de clustering sur un ensemble de joueurs de football
Le clustering, ou partitionnement, de données est une des problématiques les plus récurrentes depuis la démocratisation de la data science. Elle consiste à appliquer des algorithmes d’apprentissage automatique permettant de diviser un groupe hétérogène de données en sous-groupes, de manière à ce que les données considérées comme les plus similaires soient associées. Ces derniers sont ensuite étudiés dans le but de comprendre leur comportement. Les domaines d’application sont divers : l’analyse financière, le marketing, la démographie, etc.
Durant cette période de l’année qui est synonyme de mercato hivernal, les joueurs de football sont évalués et valorisés selon différents attributs tels que leur âge, leur efficacité devant le but, leur vision du jeu ou bien même leurs caractéristiques techniques et physiques.
L’objectif de cet article est triple. Pour commencer, celui-ci a pour but de présenter une démarche pédagogique et ludique afin de suivre une méthodologie de clustering sur un ensemble de données caractérisant des joueurs de football en 2016. Ensuite, en projetant les données correspondant à l’année 2020, une comparaison sera effectuée entre les données de 2016 et de 2020 permettant ainsi d’identifier les transferts de joueurs inter cluster durant la période étudiée. Enfin, les résultats des deux premières parties seront utilisés afin de fournir une publication listant des joueurs à fort potentiel financier.
Les données utilisées sont issues des jeux de la franchise FIFA et plus particulièrement des opus 2016 et 2020 [1]. Ces dernières résultent d’un processus d’évaluation basé sur le volontariat généralement réalisé par des passionnés ou acteurs ayant évolué ou évoluant dans le milieu. Le nombre d’évaluateurs variant selon les championnats, les clubs ou bien les joueurs, les données subissent ensuite une harmonisation afin d’éviter des incohérences. L’objectif est de réaliser un jeu de données objectif décrivant au mieux le monde du football à un instant précis [2].
La première étape consiste à se doter de tous les outils nécessaires pour réaliser le clustering énoncé ci-dessus. Le langage et l’environnement de développement utilisés sont respectivement Python et Jupyter Notebook. Concernant les bibliothèques requises : sklearn, numpy et pandas seront les armes principales.
L’échantillon se compose des deux-cents joueurs de champ les mieux notés de FIFA 2016. En effet, les évaluateurs ayant tendance à se focaliser sur les grands clubs et les grands joueurs, ce sont donc ces derniers qui ont un risque d’incohérence faible. Les gardiens de but ayant des caractéristiques vraiment propres à leur rôle sont écartés de l’analyse.
La majorité des variables utilisées sont des chaînes de caractères de la forme “x+k” où x est un entier et k un entier relatif. x est la note attribuée lors de la dernière observation et k représente un ajustement suite aux performances des joueurs. Si les joueurs réalisent de bonnes performances, k sera supérieur à 0, et inversement. Afin de rendre exploitables ces variables, on applique la fonction eval sur l’intégralité des variables. Cette dernière permet d'exécuter une chaîne de caractères telle une instruction python. Ainsi, eval(“80+2”) sera remplacé par 82.
Certaines variables sont définies sur des référentiels différents ce qui les rend de ce fait difficilement comparables les unes par rapport aux autres. Pour s’affranchir de cette contrainte, une transformation affine appelée Centrage et Réduction est appliquée. Elle consiste pour l’ensemble des variables étudiées à imputer leur moyenne et à diviser le résultat par leur écart type. Cette transformation permet de générer des variables ayant une moyenne à 0 et un écart type à 1 tout en conservant les propriétés de corrélation entre ces dernières.
Par ailleurs, l’algorithme de clustering, présenté dans la partie suivante dépend de la proximité entre chaque individu étudié. Arbitrairement, cette proximité est mesurée à l’aide la distance Euclidienne. Étant utilisée au quotidien, cette dernière se traduit comme une des mesures les plus intuitives. Dans les espaces à grandes dimensions, autrement dit les problèmes avec beaucoup de variables, la distance euclidienne perd tout son sens.
Il est donc pertinent de réaliser une technique de réduction de dimensions telle que l’Analyse en Composantes Principales (ACP) [3]. Cette dernière consiste à transformer des variables corrélées (ou liées) en nouvelles variables décorrélées les unes des autres. Cependant, il est important d’énoncer que cette technique entraîne une détérioration de la représentation des donnée de par la perte d’information.
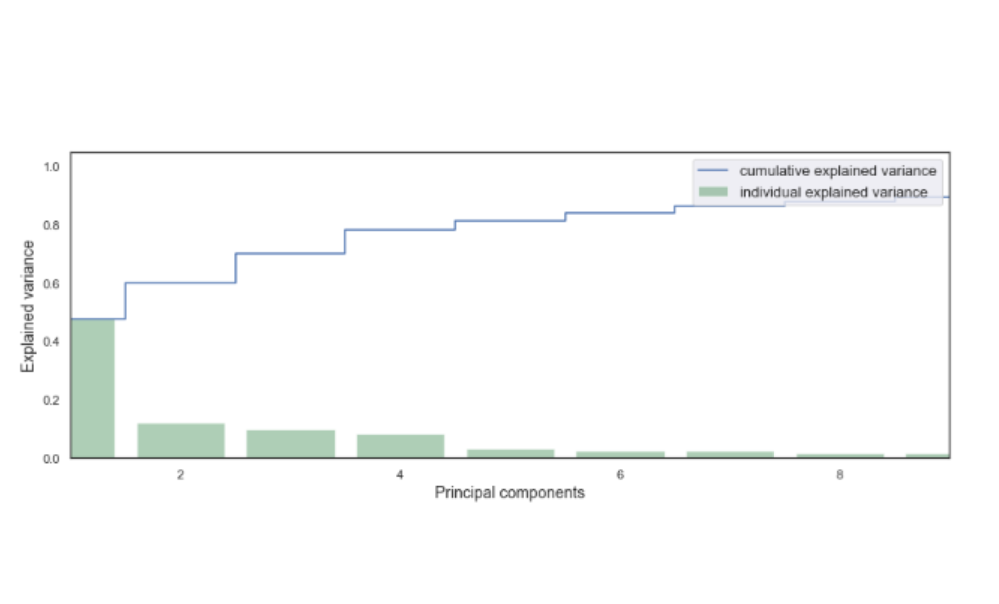
Une fois l’ACP réalisée, il est maintenant nécessaire de choisir le nombre de composantes. Pour rappel, il est impératif de ne pas reconstruire un espace à grande dimension. Un nouvelle problématique apparaît : maximiser l’information absorbée par les composantes tout en minimisant le nombre de composantes à embarquer. Naturellement, il faut donc embarquer les composantes ayant absorbé beaucoup d’information telles que les composantes principale 1, 2, 3 et 4. Celles-ci sont visibles sur le diagramme en barre ci-dessous absorbant respectivement 48%, 12.1%, 9.5% et 8% d’information. Afin de rester dans un espace perceptible, le choix a été de prendre les trois premières composantes qui absorbent à elle trois près de 70% de l’information.
Une fois le nouveau jeu de données constitué uniquement des composantes principales présentées ci-dessus, l’application d’un algorithme de clustering est maintenant cohérente. L’algorithme retenu est le k-mean [4]. Il permet de regrouper en K groupes homogènes distincts les individus du jeu de données. Ainsi, les joueurs ayant des caractéristiques proches se situeront dans le même cluster. A noter qu’un joueur de football ne peut appartenir qu’à un et unique cluster.
Le paramètre K est à définir, ce qui soulève donc le sujet suivant : trouver un K qui minimise suffisamment la variance à l’intérieur d’un cluster. De même que pour le choix des composantes, il faut augmenter la cardinalité de K tant que l’ajout d’un cluster fait sensiblement baisser l’inertie présente dans l’intégralité du jeu de données. Cette méthode est appelée “Elbow Method”. D’autres méthodes existent pour déterminer le K optimal : la classification ascendante hiérarchique, etc. De ce fait, à partir du 10ème cluster, l’inertie ne diminue presque plus. Ainsi, le nombre de cluster choisi est 10.
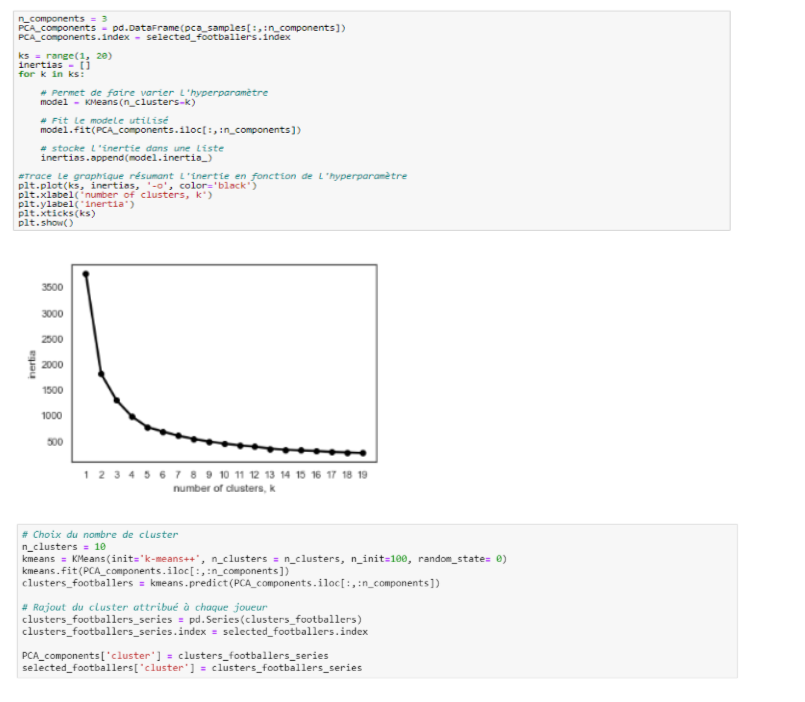
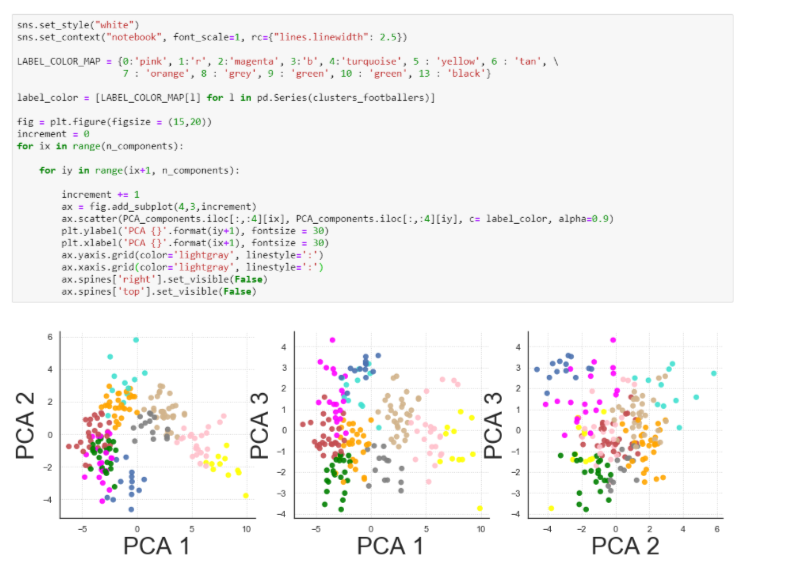
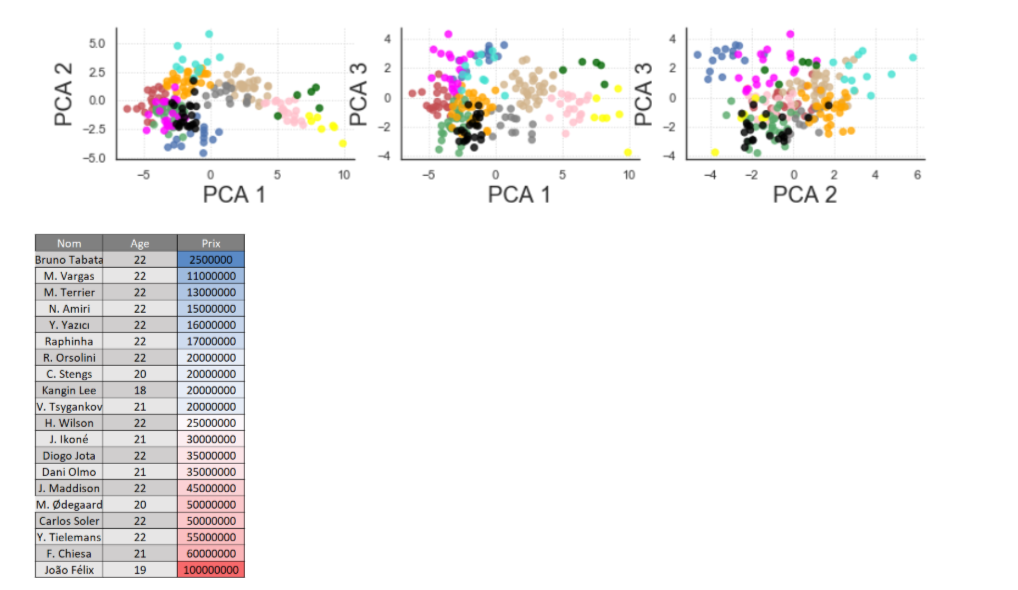
Du fait que les données sont maintenant projetées dans un espace à 3 dimensions, il est possible de visualiser les clusters selon les 3 plans composés des couples distincts de composantes principales. L’utilisation d’une figure en 3 dimensions peut entraîner une perte d’information selon l’angle de perception. Pour un travail de restitution, il est préférable de proposer plusieurs plans en 2 dimensions.
Suite au clustering des données reflétant le niveau des joueurs lors de l’année 2016, 10 clusters ont été générés. La heatmap ci-dessous résume de façon macroscopique le contenu de ces derniers. Une note moyenne de chaque variable est calculée afin de faire ressortir les traits discriminants de chaque clusters. Les couleurs vert et rouge signifient respectivement que l’ensemble des joueurs composant un cluster possède soit un niveau élevé soit un niveau faible pour une caractéristique étudiée. Un teint jaune révèle un niveau moyen. Les joueurs évoluant dans les mêmes registres de jeu sont regroupés ensembles ce qui confirme que les clusters sont correctement établis.
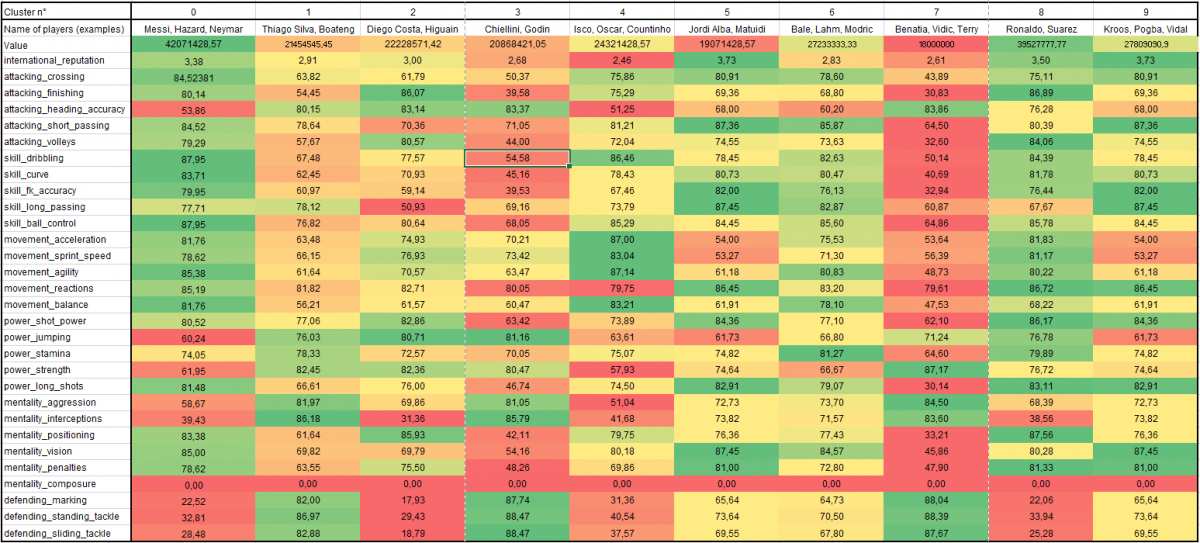
Cluster 0, couleur rouge : Ce cluster a absorbé les joueurs offensifs polyvalent capable d’évoluer à tous les postes de l’attaque. Selon les variables étudiées, ce sont des joueurs ayant un bon contrôle du ballon, une capacité à dribbler pour éliminer un joueur tout en étant de très bon tireur de coup franc.
Cluster 1, couleur beige terne : Les joueurs défensifs intégrant ce cluster sont des profils défensifs considérés comme techniques. D’après les données FIFA 16, ce sont des joueurs ayant surtout un très bon sens de l'anticipation.
Cluster 2, couleur bleu : Ce cluster regroupe les “renards des surfaces”. Ce sont des joueurs qui se positionnent correctement afin de se mettre dans les meilleurs conditions pour conclure une action.
Cluster 3, couleur rose : En plus du cluster n°1 (beige terne, défenseurs), le cluster n°3 regroupe aussi des défenseurs. La distinction se réalise du fait que les joueurs de ce cluster sont particulièrement habiles dans le jeu aérien et moins complet dans les phases de jeu. Ce dernier point est visible à travers le heatmap qui révèle beaucoup de caractéristique tendant vers le orange.
Cluster 4, couleur vert : Les joueurs ayant des caractéristiques propres au poste de meneur de jeu sont présents dans ce cluster. Ils se distinguent par une capacité d’accélération, de conservation de la balle et possèdent une certaine vivacité lorsqu’ils doivent prendre une décision.
Cluster 5, couleur gris : Les arrières latéraux se situent dans cette partition de donnée. Il est intéressant de constater que Matuidi, qui est un milieux relayeur, possède d’après les données FIFA 16 des caractéristiques avoisinant celles de Jordi Alba et Dani Alves.
Cluster 6, couleur orange : Ce cluster est représenté par les joueurs polyvalent du milieux de terrain. Aucun attribut ne tend vers un teint rougeâtre.
Cluster 7, couleur jaune : Ce cluster rassemble des défenseurs physiques qui ont la particularité d’avoir “un mental de guerrier” comme en témoigne une note élevée concernant les variables mentality_agression et power_strength.
Cluster 8, couleur magenta : Les grands attaquants sont réunis dans ce cluster. D’après les données, ces joueurs excellent devant le but et dans la dernière passe. Finalement, ce cluster se rapproche du cluster n°0 (rouge, offensifs polyvalents) à la seule différence que les joueurs du cluster n°8 sont plus attirés par le but.
Cluster 9, couleur turquoise : D’après les données, les milieux relayeurs sont concentrés dans ce cluster. Ces joueurs se caractérisent par une capacité à se projeter vers l’avant pour se rapprocher du but, une note élevée concernant les coups de pieds arrêtés, une bonne frappe de balle et une excellente vision de jeu.
Comme expliqué au début de cet article, l’objectif de cette partie est d’identifier les transferts inter cluster entre les années 2016 et 2020 pour identifier une liste potentielle de joueurs à forte valeur ajoutée. Après projection des données de l’opus de 2020 à travers les composantes principales créées à l’aide des données des joueurs en 2016, certains canaux de transfert se révèlent.
Le tableau ci-dessous représente les transferts inter cluster effectués entre l’année 2016 et 2020.
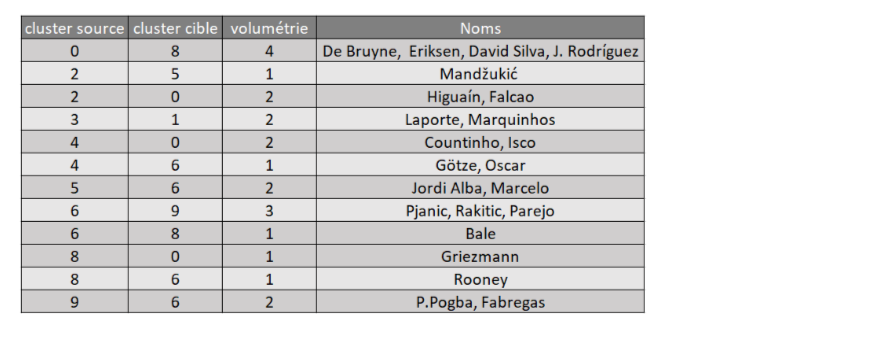
D’après la heatmap, les clusters 0 et 8 regroupent les joueurs ayant la meilleure valeur marchande. Il peut être intéressant, pour un club voulant faire du trading de joueurs, de comprendre comment sont alimentés les clusters en fonction du temps. Les canaux de transferts alimentant ces deux premiers sont les suivant :
Ainsi, un club qui veut générer de la rentabilité a tout intérêt à recruter des jeunes joueurs appartenant aux clusters 4 ou 6 (couleurs vert et orange). En effet, cibler des jeunes joueurs semble plus pertinent du fait qu’ils aient une grande marge de progression.
Après avoir filtré les joueurs pour conserver uniquement ceux qui ont un âge inférieur à 23 ans, voici une projection sur les composantes principales et une liste de joueurs possédant ou susceptibles de développer une forte valeur marchande.
Ce tutoriel nous permet de réaliser une analyse descriptive des données en réalisant un clustering sur celles-ci. Cette dernière a permis dans un second temps d’étudier les canaux d’échange inter cluster. Puis, l’exploitation de ces canaux a permis de lister des joueurs pouvant fournir une forte rentabilité. Raphinha, déjà acheté par Rennes pour 21 millions d’euros lors de l’été 2019 alors qu’il en valait 8, est un candidat sérieux. Étant évalué en janvier 2020 à 17 millions d’euros, son prix a été multiplié par deux. Au vue de la saison 2019-2020 qu’il réalise, il est possible que ses caractéristiques commencent à coulisser vers celles des clusters 0 ou 8 et que par la même occasion son prix augmente.
Pour dénicher les étoiles de demain, nous pouvons nous concentrer sur les clusters alimentant les clusters 0 ou 8. Appliquer une telle méthode sur un échantillon plus large de joueurs pourrait effectivement mettre en lumière certaines pépites.
Sources :
[1]https://www.kaggle.com/stefanoleone992/fifa-20-complete-player-dataset
[2]https://mcetv.fr/mon-mag-culture/mon-mag-gamers-time/fifa-18-calcul-notes-joueurs-2809/
[3]https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
[4]https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html

