Observatoire Canadien de l'Hydrogène : observer,…

Traitement automatique du langage naturel sur les Tweets
La communication sur Twitter est un incontournable pour tous les dirigeants politiques. Cela leur permet des interactions instantanées et sans intermédiaire avec leur électorat. Un exemple frappant est celui du président des Etats-Unis : Donald Trump. Lors de ses 33 premiers mois à la Maison Blanche, il a tweeté plus de 11 000 fois.
Avec les élections municipales qui approchent, nous avons voulu nous intéresser plus en détails aux actions faites sur Twitter par les candidats à la mairie de Paris. Nous avons concentré notre analyse sur les principaux candidats (liste des candidats datant du 07 Février 2020, classés de gauche à droite sur l’échiquier politique):
Comme pour tout projet de Data Science, nous avons commencé par une analyse descriptive sur les actions de tous les candidats puis nous avons poursuivi avec de la modélisation sur les deux candidates principales avec de l’analyse de sentiments avec la nouvelle architecture d’apprentissage profond pour le TALN (Traitement Automatique du Langage Naturel) en français: FlauBERT et de l’analyse des thèmes avec l’algorithme Latent Dirichlet Allocation.
Afin de collecter les différentes actions des candidats, nous avons utilisé la librairie Python Tweepy. Nous avons ainsi pu récolter toutes les 19 375 actions effectuées entre le 07 août 2019 et le 07 Février 2020.
A ce stade, nous ne distinguons pas les Tweets, les Retweets, les Quotes ou les Replys mais nous le ferons plus tard dans l’analyse. Nous utilisons le terme générique “action” pour nommer une de ces quatre actions ci-dessus. Pour rappel, voici l’explication du vocabulaire de Twitter:
Pour les Tweets des candidats, nous compterons également le nombre d’interactions qu’ils ont eues avec les autres utilisateurs de Twitter:
Comme présenté ci-dessous, nous observons une forte différence entre les candidats dans leur nombre d’actions sur Twitter. De façon générale, les candidats de gauche ont tendance à utiliser plus Twitter que les candidats colorés plus à droite. En tant que maire en place, A. Hidalgo est la candidate qui communique le plus sur Twitter avec plus de 7 000 actions.

NB: Dans tous les graphiques, les candidats sont nommés en accord avec leur nom figurant sur leur compte Twitter au moment de la rédaction de l’article. De plus, la couleur choisie est celle du site internet du candidat.
Chaque action collectée possède 33 variables dont le texte, les hashtags utilisés, le nombre de retweets et de “Favorite” obtenus, la date de création. Nous avons nettoyé les données afin notamment de supprimer les doublons (issus du processus de récolte des données) et d’ajouter des variables nous permettant d’identifier la nature de chaque action.
Afin d’analyser les sentiments à l’égard des deux principales candidates, nous avons également récolté les Tweets contenant les hashtags #Hidalgo et #Dati entre le 26 Janvier 2020 et le 09 février 2020.
Si nous analysons plus en détails les actions des candidats, nous comprenons pourquoi certains candidats semblent beaucoup plus actifs que d’autres : ils n’utilisent pas Twitter de la même façon. En effet, les candidats actifs font beaucoup de Retweets, ce qui est une action sans effort car aucun texte n’est à écrire. Le meilleur exemple est celui de A. Hidalgo : plus de 80% de ses actions sont des Retweets (cf ci-dessous).
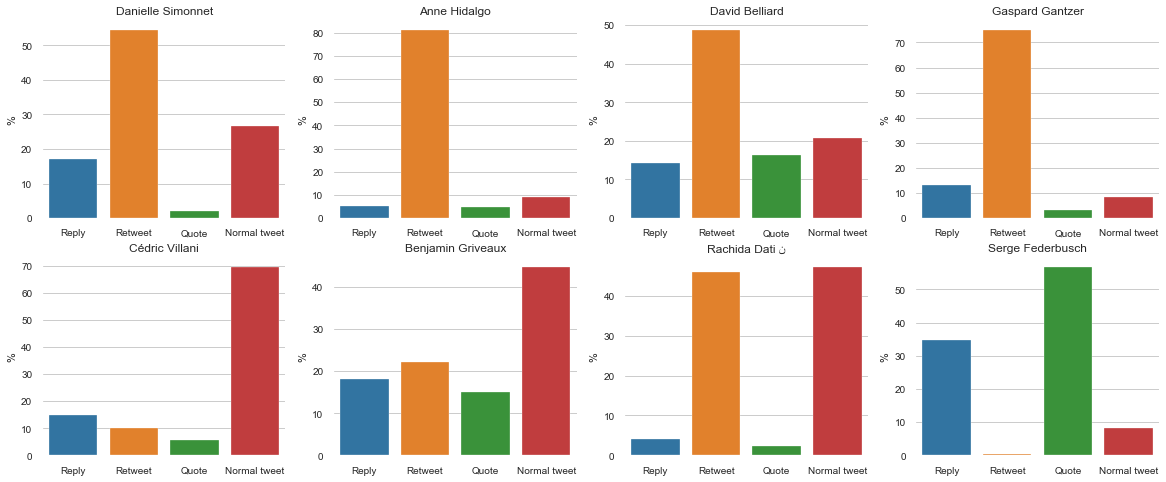
Nous pouvons également analyser l’évolution du nombre d’actions des candidats en fonction du moment de l’année. Ci-dessous, nous avons calculé le nombre d’actions de chaque candidat sur des périodes de 2 semaines.

Nous observons que le nombre d’actions a augmenté significativement après les vacances d’été pour tous les candidats avec un ralentissement pendant les vacances de Noël. Un point intéressant est l'augmentation du nombre d’actions du candidat S. Federbusch après l’annonce officielle de la candidature de R. Dati pour Les Républicains et après celle du marcheur dissident C. Villani. En revanche, la première grande grève contre la réforme des retraites n’a pas provoqué d’effet significatif sur l’activité des candidats sur Twitter.
Il est intéressant de regarder le contenu créé par les candidats mais ce qui est le plus important pour les dirigeants politiques c’est la résonance de ce contenu avec leur électorat. Ci-dessous, nous avons calculé le nombre de “Retweet” et de “Favorite” moyen pour les Tweets de chaque candidat.

Nombre de Retweets et Favorites des candidats
Bien que n’étant pas supporté par un parti politique, C. Villani bénéficie de beaucoup d’interactions avec plus de 300 “Favorite” en moyenne sur ses Tweets. Le faible nombre de Tweets écrits par C. Villani (312 sur la période étudiée) peut expliquer ceci. En effet, il tweete probablement que lorsqu’il a de grandes annonces à faire ce qui génère beaucoup d’interactions.
L'analyse de sentiments vise à identifier les opinions d'un texte donné. Les opinions peuvent être très diverses mais dans notre cas, nous avons essayé de classer le texte selon 4 critères : très négatif, négatif, positif ou très positif.
Nous allons maintenant nous concentrer sur les deux candidates ayant les intentions de vote les plus élevées: A. Hidalgo et R. Dati. Nous avons effectué une analyse des sentiments sur leurs propres Tweets et sur les Tweets contenant leurs hashtags (#Hidalgo et #Dati).
Pour effectuer l'analyse des sentiments, nous avons décidé d'utiliser des techniques d'apprentissage profond (réseau de neurones). En novembre 2019, un modèle similaire à BERT a été partagé en open source: FlauBERT. Il atteint d’excellents résultats dans de nombreuses tâches de TALN (Traitement Automatique du Langage Naturel), y compris sur la classification de phrases (la tâche requise pour l'analyse des sentiments). Nous avons spécifiquement utilisé l'implémentation huggingface de FlauBERT sur PyTorch.
Comme pour les tâches de vision par ordinateur avec VGG, les réseaux de neurones TALN sont pré-entraînés sur de grandes bases de données et peuvent être réutilisés avec un entraînement plus léger sur des tâches spécifiques. Nous avons utilisé les poids pré-entraînés de FlauBERT et avons ré-entraîné avec une carte graphique la dernière couche de neurones sur notre tâche spécifique : l’analyse de sentiments. Cette technique a de nombreux avantages car elle requiert :
Pour entrainer la dernière couche de notre modèle, nous avions besoin de données labellisées: des textes en français avec le sentiment associé. Nous avons utilisé le Webis Cross-Lingual Sentiment Dataset 2010 qui a des textes labellisés en anglais, français, allemand et japonais. Il contient 6 000 avis Amazon en français avec sa note associée (1, 2, 4 ou 5 étoiles) pour l'entraînement. Les commentaires avec trois étoiles ont été retirés à cause de l’indécision sur le sentiment associé au texte.

Après 4 époques sur notre GPU, notre modèle a atteint un score de 0,556 sur le coefficient de corrélation métrique de Matthews avec quatre classes (représentant les sentiments «très négatif», «négatif», «positif» et «très positif»). Le coefficient de corrélation de Matthews prend une valeur entre -1 et 1 (la valeur minimale dépend de la vraie distribution pour les cas multi-classes); 1 étant la précision parfaite. Nous avions maintenant notre modèle affiné sur la tâche d'analyse des sentiments et l'avons appliqué sur les Tweets.
Les Tweets écrits par A. Hidalgo, en tant que maire de Paris actuel, sont globalement très positifs (voir ci-dessous). C'est compréhensible car elle fait principalement la promotion de ses propres actions durant son mandat et ainsi que celle de ses prochains projets.
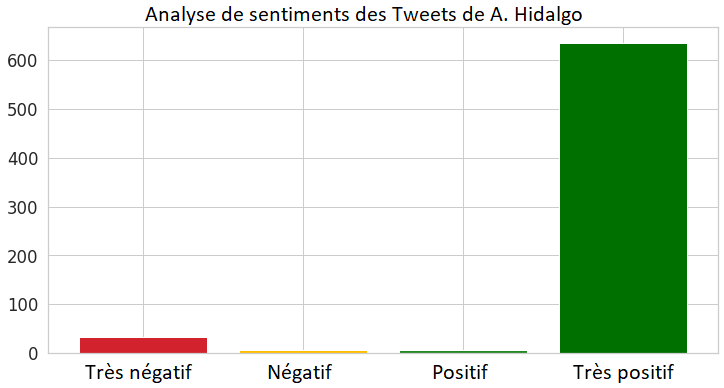
Au contraire, R. Dati écrit beaucoup plus (en proportion) de Tweets «très négatif» et «négatif», car elle conteste le mandat de la maire actuelle tout en proposant ses nouvelles idées.
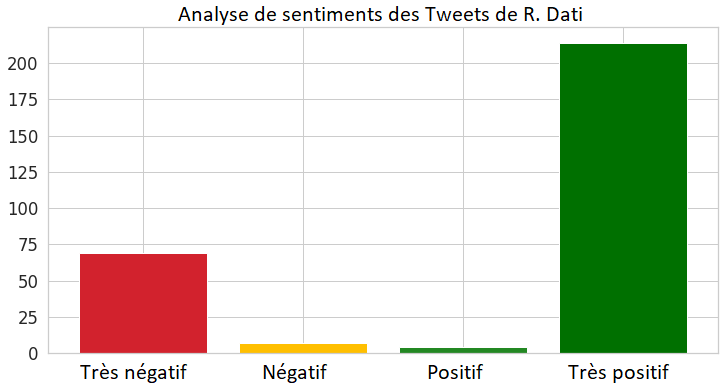
Après avoir analysé les Tweets rédigés par les candidates, il est également intéressant d'analyser le sentiment des Tweets les mentionnant. Les Tweets entre le 26 janvier et le 9 février ont été utilisés pour analyser le sentiment envers les deux principales candidates. Nous avons observé beaucoup de Tweets très négatifs. Cependant, R. Dati a collecté en proportion beaucoup plus de Tweets «très positif», ce qui correspond à sa bonne dynamique dans les sondages lors de la période de collecte des Tweets.
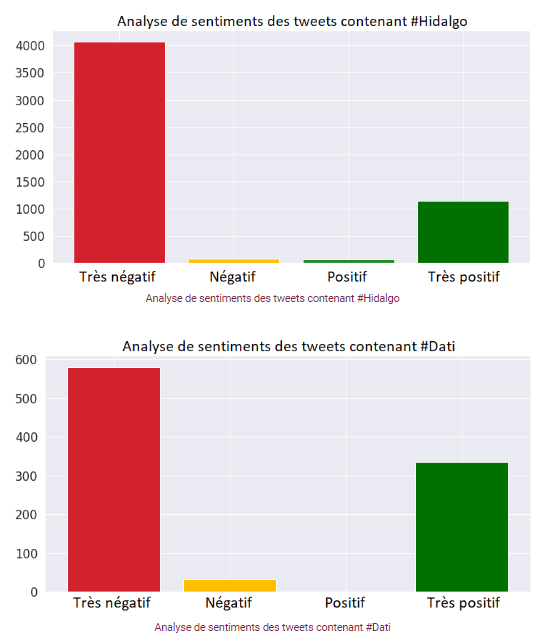
NB: Nous observons que les classes extrêmes «très positif» et «très négatif» sont beaucoup plus représentées. Cela peut être dû à l'attitude très polarisée des utilisateurs sur Twitter, mais cela peut également être dû en partie aux données d’entraînement qui n’ont pas des classes parfaitement équilibrées. Pour un modèle de production, un travail supplémentaire devrait être effectué sur ce sujet pour rechercher les causes exactes.
Nous voulions également identifier les thèmes prédominants pour les deux candidates les mieux placées en intention de vote. Pour ce faire, nous avons utilisé l'algorithme LDA (Latent Dirichlet Allocation) pour identifier dix thèmes par candidate en fonction de leurs Tweets.
Nous pouvons avoir une idée des thèmes identifiés en analysant les mots les plus représentatifs de chaque thème. Dans les visualisations ci-dessous, la barre grise indique la fréquence globale du mot dans le corpus (tous les tweets pour le candidat sélectionné) et la barre rouge indique la fréquence du mot dans le thème sélectionné.
Pour R. Dati, le premier thème concerne la délinquance. Nous pouvons relier ce thème au débat actuel sur la police municipale à Paris. En tant que candidate de droite, il n'est pas surprenant que ce thème arrive en premier pour R. Dati avec plus d'un quart de ses mots liés à ce thème.

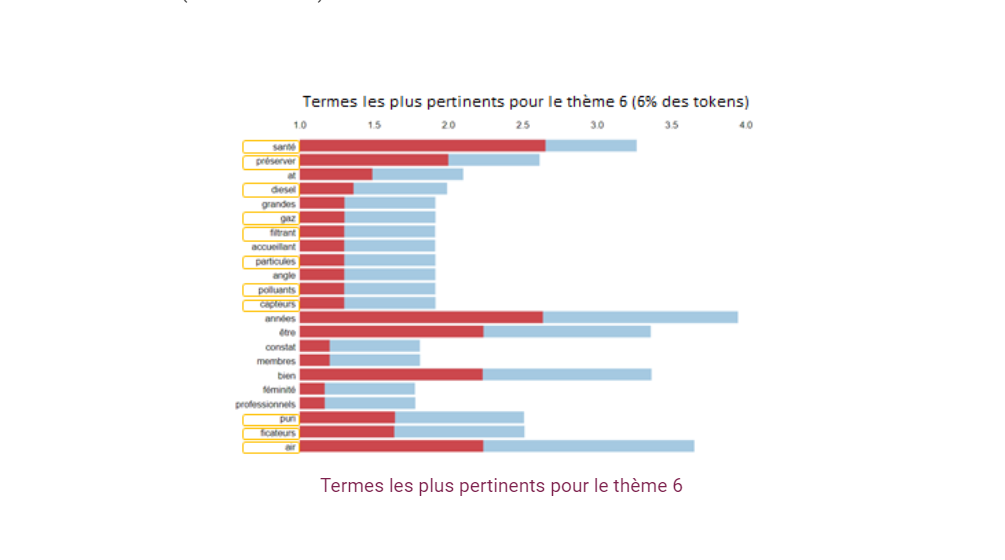
En revanche, le sujet autour de la pollution de l’air, que nous relions au thème n°6, ne concerne que 6% de ses mots (cf ci-dessous).
En tant que candidate de gauche, il n'est pas surprenant de découvrir des sujets sur l'écologie dans les Tweets d'A. Hidalgo. Ce sujet est également en corrélation avec le travail qu'elle a fait pour avoir des pistes cyclables comme nous pouvons le voir avec les mots «cyclable», «travaux».
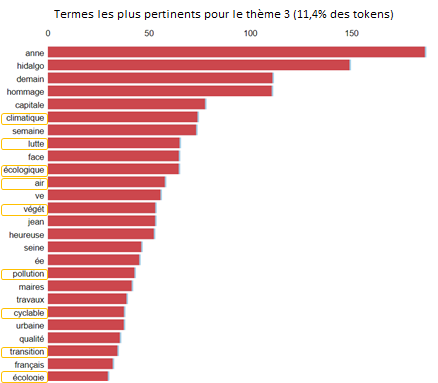
Termes les plus pertinents pour le thème 3
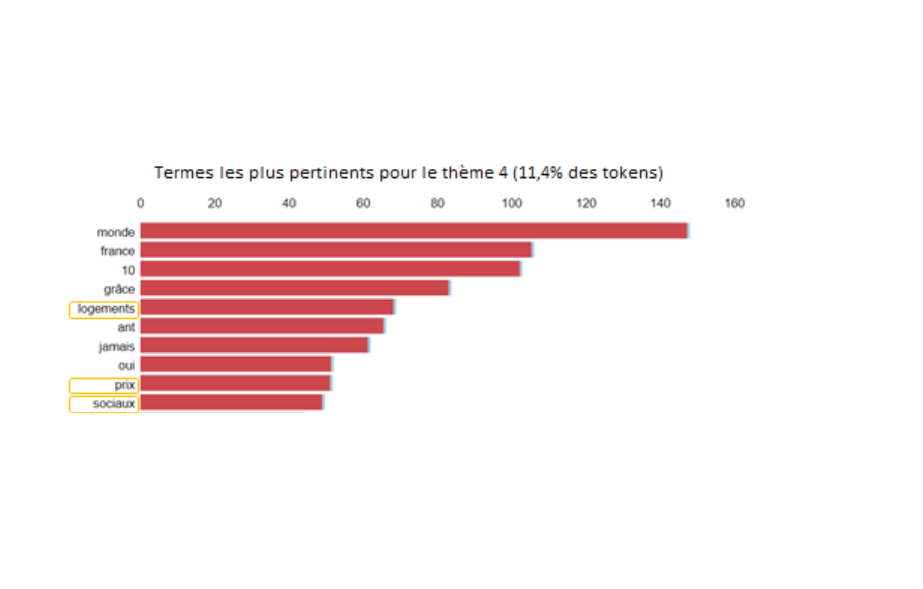
Un autre sujet classique de la gauche est le logement social. C'est un sujet clé pour A. Hidalgo, en effet le candidat communiste I. Brossat (actuel adjoint au logement) a rejoint sa liste pendant la campagne. Ce sujet représente plus de 10% de ses mots.
L'un des grands projets clés d'A. Hidalgo en tant que maire de Paris est la rénovation de 7 grandes places dont les places de la Bastille et de la Concorde. Cette rénovation vise à donner plus de place aux piétons et aux espaces végétaux. Ce sujet est également identifié par la LDA dans les Tweets de A. Hidalgo avec des mots comme «place», «bastille», «jardins», «espace» ou «concorde».
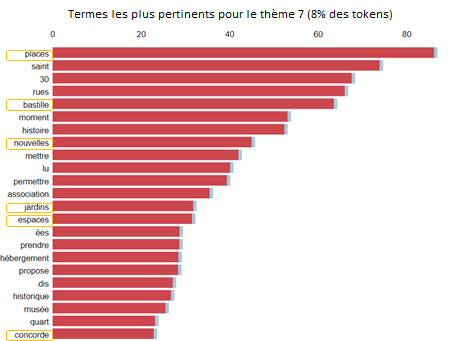
NB: Certains mots n’ont pas de sens en français, le tokenizer utilisé (FlauBERT tokenizer) pourrait être remplacé par un meilleur tokenizer.
Dans cette brève analyse, nous avons réussi à extraire quelques informations clés via un processus rigoureux de Data Science : collecte des données, analyse des données et modélisation de ces données. Nous avons utilisé une technique de Machine Learning classique, à savoir LDA, mais également une technique d'apprentissage profond avec FlauBERT pour l'analyse de sentiments.
Nous avons vu que les candidats pour la mairie de Paris n'utilisaient pas Twitter de la même façon, certains utilisant principalement des Retweets. L'analyse des sentiments dans les Tweets nous a également permis de mieux comprendre la stratégie de contenu des candidats ainsi que leur dynamique actuelle dans les sondages. Enfin, le LDA a extrait les thèmes clés de chaque candidat, nous donnant un aperçu de leurs futurs projets en tant que maire.
Sia Partners a assisté ses clients avec succès sur des missions contenant diverses tâches de TALN telles que la détection de faux avis en ligne, l'analyse de sentiments sur les avis en ligne, la qualification automatique des nouvelles régulations bancaires, des solutions Chatbot ou de Speech-to-Text.

